写给前端工程师的 MCP 入门指南
很多前端工程师第一次接触 MCP,都会有点懵:名字像协议,内容像 Agent,讨论里又总会出现 Tool、Prompt、Resource、Skill。其实没必要一开始把所有术语都啃下来,只要先抓住一句话:MCP 是让 AI 能接工具、拿数据、真的做事的一套标准方式。
如果把以前的大模型比作一个只会说话的同事,那接入 MCP 之后,它就可以获得查系统、调接口、读文件的能力了。它不再只是回答问题,而且还可以在授权范围内去帮你完成一些操作,这也是 MCP 被越来越多 AI 开发工具采用的重要原因之一。
什么是 MCP
MCP 全称 Model Context Protocol,是一个开放协议,用来连接 LLM 应用与外部数据源、工具和系统能力。
如果用前端熟悉的方式理解,HTTP 解决的是浏览器如何和服务器通信,而 MCP 解决的是 AI 应用如何和工具、资源、上下文通信。
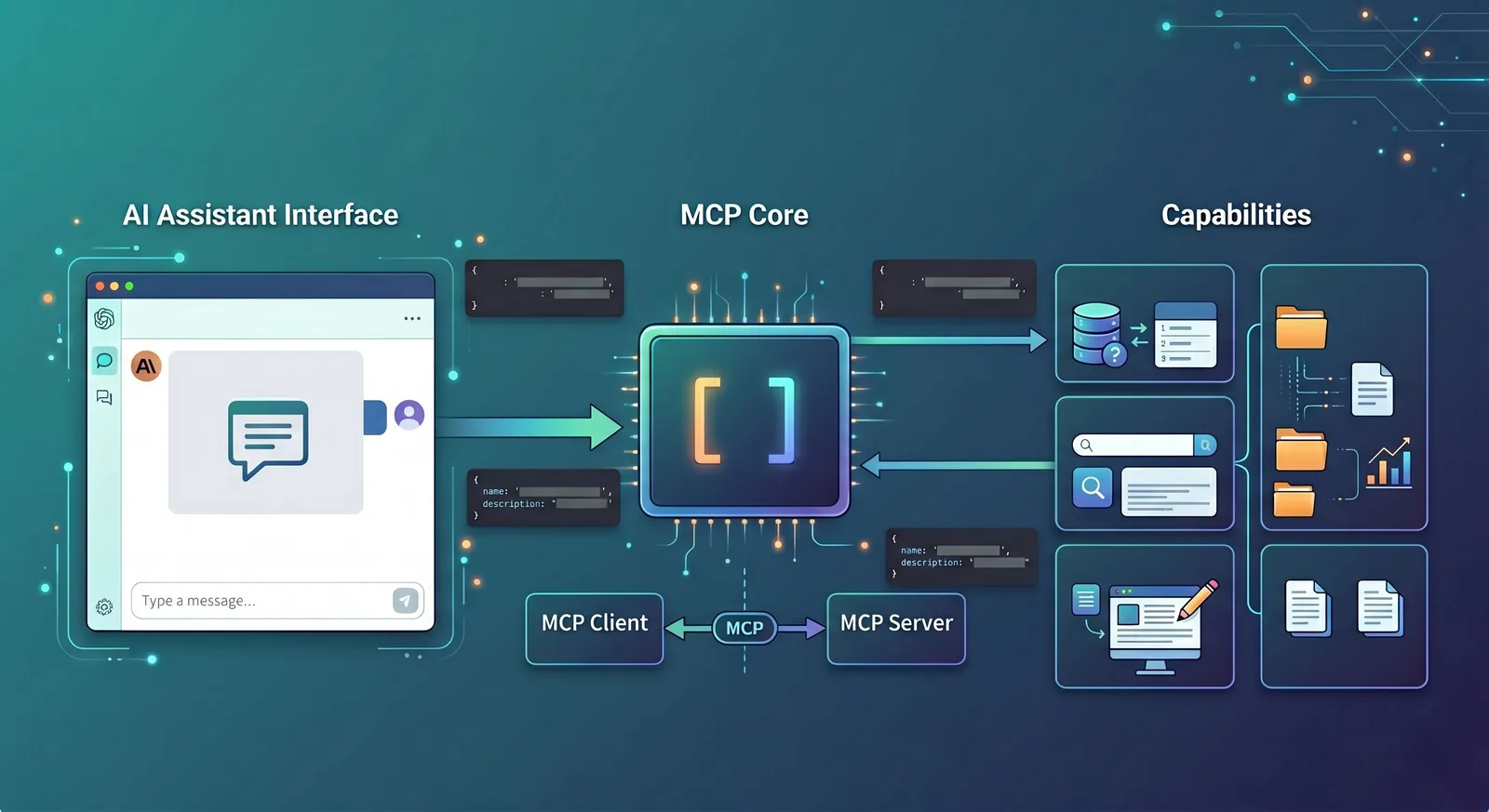
官方架构文档把通信角色分成 Host、Client 和 Server:Host 是发起连接的 LLM 应用,Client 是宿主Host里的连接器,Server 是工具和上下文能力的提供者。
这个设计和前端熟悉的“宿主应用 + SDK + 服务端”非常接近。你可以把它理解成:Host 负责界面和模型,Client 负责按协议通信,Server 负责真正提供能力。
先看一个最直观的例子
假设你做了一个后台系统,右下角放了一个 AI 助手。用户问它:“今天新增了多少订单?”
如果没有 MCP,这个助手通常只能停留在聊天层:要么根据训练数据猜一个结果,要么你自己再额外写一套工具调用格式,把数据库查询接口和权限逻辑硬接进去。
如果用了 MCP,流程就清晰很多。AI 助手先去问某个 MCP Server:“你这边有什么工具?” 服务端返回一组工具列表,比如 get_today_orders、get_order_detail、export_report,每个工具都带着用途说明和参数 schema。
接着模型看到用户的问题后,选择调用 get_today_orders。服务端查完数据库,把结果返回给 AI,再由 AI 用自然语言回复“今天新增 128 单”。这就是 MCP 最典型的使用方式:先发现工具,再调用工具,再把结果组织成用户能理解的话。
Host、Client、Server 到底分别是谁
这三个词经常一起出现,但一点都不难。可以拿“外卖平台”来类比:Host 像外卖 App,Client 像 App 里的调度系统,Server 像真正出餐的商家。
放到 MCP 里:
Host 是你直接看到的 AI 应用,比如 Claude Desktop、Claude Code、某个 IDE 插件,或者你自己做的 Web AI 页面。
Client 是 Host 内部负责按 MCP 协议和外界通信的那一层。
Server 是真正提供能力的一方,比如日志服务、文件系统适配器、数据库查询服务、GitHub 工具服务。
举个开发场景。假设你在 VS Code 里用 AI 编程助手,让它“帮我看看当前项目里哪个接口超时最多”。此时 VS Code 里的 AI 助手是 Host,助手内部负责协议通信的是 Client,能访问日志、代码仓库、监控平台的那些能力提供方,就是 MCP Server。
Tool 是你最先该理解的东西
MCP 里最重要的东西不是 Prompt,也不是 Resource,而是 Tool。因为绝大多数“AI 真正开始做事”的体验,都是从 Tool 开始的。
你可以把 Tool 理解成一个“给 AI 用的接口”。它通常会包含三样东西:工具名、用途说明,以及一份参数 schema,也就是参数的结构定义。
比如一个天气工具,可能长这样:
name:
get_weatherdescription: 查询某个城市当前天气
input schema:
location,类型是 string,而且必填。
当客户端调用它时,会通过 tools/call 这类请求,把工具名和参数一起发过去。官方工具规范和示例都采用了这种模式。
再举一个更贴近前端的例子。你做了一个内容后台,可以给 AI 助手接三个工具:
search_articles:按关键词查文章。get_article_detail:查某篇文章详情。publish_article:发布文章。
这样用户说“把标题里带 MCP 的草稿找出来并发布最新一篇”,AI 就有机会先查列表,再取详情,再调用发布接口。你会发现,这其实就是把一组后台 API 暴露给模型去组合调用。
为什么 schema 很重要
很多人第一次看 MCP,会觉得“工具名 + 描述”就够了,为什么还非得写 schema。原因很简单:模型不是靠猜来调工具的,它需要一个清晰的参数契约。
比如你写了一个 create_user 工具,如果没有 schema,模型可能不知道 email 是不是必填,也不知道 age 到底应该传数字还是字符串。加上 schema 之后,模型和客户端都能明确知道怎么构造参数;前端也可以基于这些结构,直接生成调试表单或类型定义,这和看 Swagger 文档联调接口的体验非常接近。
这也是为什么 MCP 对前端工程师很友好。它不是一种完全靠 prompt 猜测的接入方式,而是尽量把工具能力结构化、明确化、可验证化。
一次完整调用到底怎么发生
还是用一个简单场景说明:用户在 AI 助手里输入“帮我查一下今天有多少新注册用户”。
第一步,Host 先知道自己连接了哪些 MCP Server,比如一个 analytics server。这个 server 对外提供了 get_signup_count 工具。
第二步,Client 通过 tools/list 拿到工具定义,知道这个工具需要一个 date 参数,类型是字符串。
第三步,模型判断这个问题需要调用 get_signup_count,于是客户端发一个 tools/call 请求,参数可能是 { "date": "2026-05-03" }。
第四步,Server 去查数据库或分析服务,返回结果,比如 356。然后 Host 再把这个结果组织成面向用户的话术:“今天新增注册用户 356 人。”
这个过程最关键的点在于:模型并不直接操作数据库,它始终是通过一个被明确定义好的工具来间接完成动作。这样权限、安全、审计和错误处理都更容易做。
Resource 和 Prompt,只需要先知道是干什么的
除了 Tool,MCP 里还经常提到 Resource 和 Prompt。它们确实有用,但入门阶段不用学很深。
Resource 更像“给模型看的材料”,不一定是可执行动作。比如最近 1 小时的错误日志、当前打开文件的内容、某个项目的 README,或者数据库表结构说明,这些都可以作为 Resource 提供给模型参考。
比如用户问“为什么这个接口总超时”,AI 可能不需要立刻调用很多工具,而是先读取一份日志 Resource 和一段代码 Resource,然后再分析问题。官方关于 prompts 和 resources 的示例就展示了这种把日志和代码文件一起提供给模型的用法。
Prompt 则更像可复用的任务模板。比如提供一个 git-commit prompt,输入代码改动,输出一条风格统一的提交信息;也可以有一个 explain-code prompt,专门用于解释某段代码。
如果只想记一个最简单的区别,可以这么理解:Tool 是“能做事的按钮”,Resource 是“给模型看的资料”,Prompt 是“常用工作模板”。
为什么前端会明显受益
前端受益最大的地方,不是“也能写协议”,而是交互方式会被改变。
以前页面上的 AI 助手通常只有一个输入框,能做的事情很有限。现在如果背后接了 MCP,前端就可以把很多东西显式展示出来,比如当前 AI 拥有哪些工具、这次准备调用什么工具、为什么要申请某个权限、调用结果是什么、哪一步失败了。
这会让 AI 产品更像一个“可观察、可控制的工作台”,而不只是一个黑盒聊天框。尤其在后台系统、IDE、内部工具这类场景里,用户通常更愿意看到 AI 到底做了什么,而不是只收到一句神秘的答案。
再举个贴近前端工作流的例子。你做一个日志分析页面,用户点中一条错误日志后,右侧 AI 助手自动拿到这些 context:当前服务名、错误时间范围、选中的日志片段、当前仓库分支名。
然后用户只说一句:“帮我分析一下原因。” 此时 AI 可以先读日志 Resource,再调用 search_recent_deploys、get_error_rate 这类 Tool,最后返回一段更可靠的分析。这个体验的关键,不在于模型更聪明,而在于前端把界面状态转成了模型可用的上下文。
MCP 现在在什么位置上
25-26年以来圈子里讨论得最多的,是各种 Skill、Workflow、Agent 编排,MCP 的热度看起来确实不如刚出来那会儿高。 但从工程角度看,Skill 再火,它的背后,很多时候还是 MCP 在干活。
用一个具体例子就很清楚:
Skill 像一套“客服处理退款”的话术和流程,先确认订单,再查支付状态,再核对风控,最后给出处理结果。
MCP 则像“客服系统背后的统一接口层”,帮你连上订单服务、支付服务、风控服务,让每一步“去查一下”都有对应的工具可以调。
换成开发场景也是一样:
Skill 可以定义“如何做一次代码审查”,先看 diff,再看测试,再看错误日志,最后生成审查意见。
真正去拉 diff、查 CI、读日志的动作,通常是通过 MCP 暴露出来的工具来完成;Skill 负责的是“按什么顺序用哪些工具”,而 MCP 负责“这些工具怎么连、怎么调、怎么拿结果”。
所以现在的格局更像是:对外宣传和产品卖点更多在讲 Skill 有多聪明、流程多自动化;但在底层、在代码里,MCP 依然是那层稳定的“接线板”,把模型和各种业务系统、安全网关、数据库、日志平台连在一起。
它的名字也许没有 Skill 那么热,但只要你在做的是“让 AI 真正操作系统、查真实数据”的产品,协议层这块就必须有人扛,而 MCP 正是在很多项目里扮演这个安静但关键的角色。
MCP 和 Skill 的区别
如果只用一句话区分:MCP 解决“工具怎么接”,Skill 解决“任务怎么做”。
还是拿“代码审查助手”举例。
如果现在关心的是:怎么让 AI 访问 Git diff、怎么查 CI 结果、怎么读 lint 报告,那你面对的是 MCP 问题,因为这些都属于“把能力接进来”。
但如果关心的是:代码审查先看什么、哪些风险要优先提示、输出结果按什么格式写、什么情况下要建议补测试,那这更像 Skill 问题,因为它是在定义“这件事该怎么做”。
现实里两者通常会配合出现。MCP 负责连 Git、CI、日志平台,Skill 负责固化“代码审查流程”;但作为入门理解,只要先把这条边界分清楚就够了。
它为什么值得学
MCP 值得学,不是因为它是一个新名词,而是因为它把 AI 产品开发里最容易混乱的一层做了标准化:工具发现、参数描述、上下文传递和执行调用。
当这层被标准化之后,前端工程师就不必每做一个新 AI 产品,都重新发明一套“模型如何接后端能力”的协议。
更重要的是,这种标准化会让前端的职责边界变得更有意思。页面不再只是输入输出的容器,而会逐步成为 AI 行为的控制台:展示工具、解释状态、呈现计划、申请授权、反馈结果。
这让前端工程师在 AI 产品里不只是“接个 SDK”,而是真正参与定义人机协作的交互方式。
结语
如果只用一句话概括,MCP 的价值就是:它让 AI 应用第一次拥有了一层相对统一、可复用、工程化的“外部能力接入层”。
对于前端工程师,理解它并不需要先成为 AI 专家,只需要把它看成一种新的协议层,一种让界面、模型和业务系统能够协同工作的标准连接方式。
在 Google 上继续关注
把 HeyBinyang 添加为 Google 首选来源
如果你愿意继续在 Google 里读到我的更新,可以把这个站点添加为 preferred source,之后更容易在相关内容场景里看到它。
SHARE
分享
分享这篇文章。