code-review-graph:让 AI 代码审查更精准、更省 Token
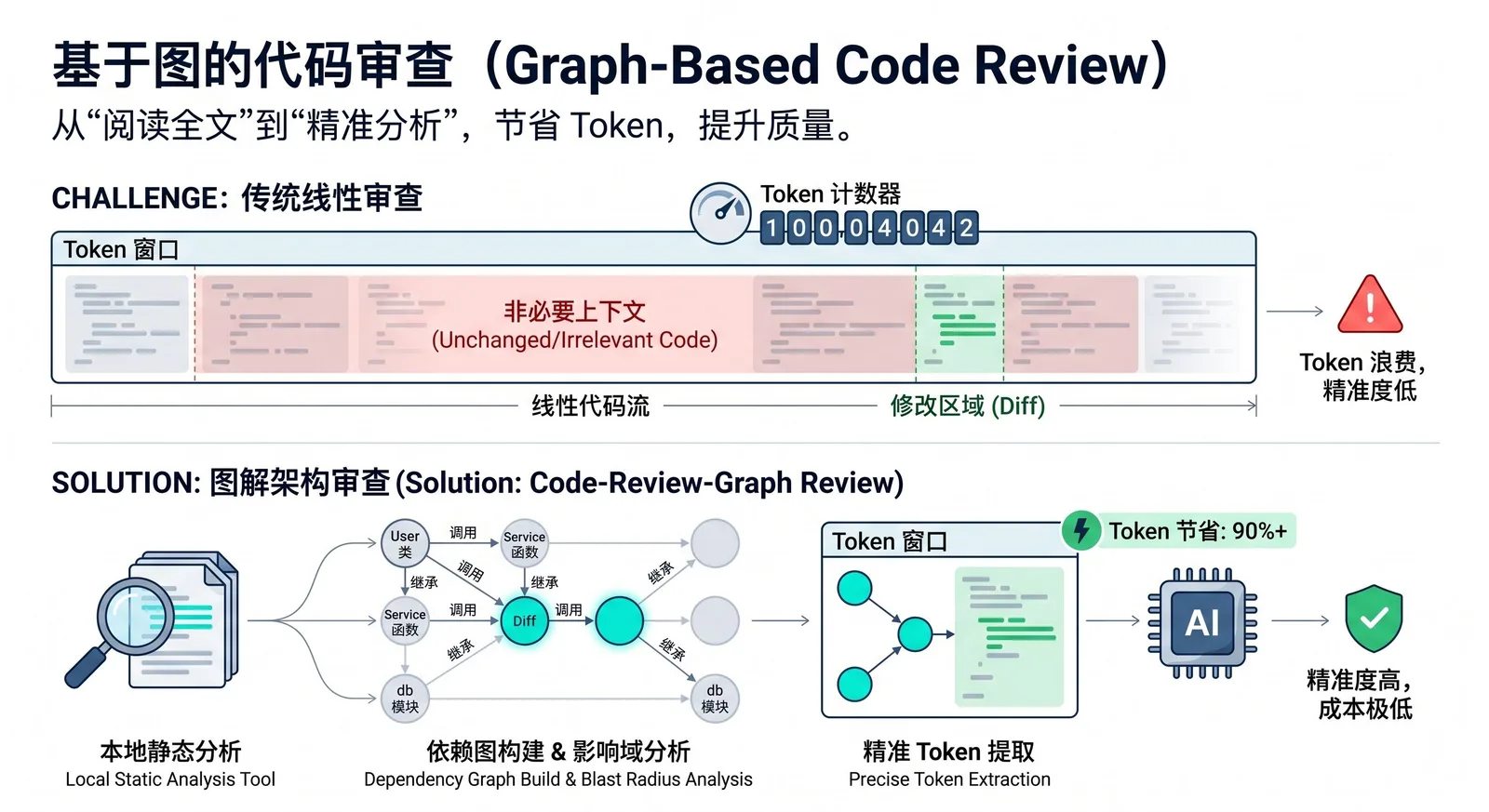
code-review-graph 是一个面向 AI 编码助手的开源工具,它会先在本地为代码库建立一张结构化“知识图谱”,再把真正相关的上下文交给 AI,从而避免每次任务都全量扫描整个仓库。 它基于 Tree-sitter 解析 AST,把函数、类、导入、调用关系和测试关系组织成图结构,再通过 MCP 提供给 Claude Code、Codex、Cursor 等工具使用。
它解决了什么问题
当前很多 AI 编码工具在做代码审查、定位影响范围或理解改动时,会反复读取整个代码库,这会带来明显的 Token 浪费与成本上升。 在一个数百文件的仓库里,即使只改了一个函数,AI 也可能需要重新扫很多无关文件,导致速度变慢、上下文噪声增加、费用变高。
code-review-graph 的思路是把“代码依赖关系”提前建模出来,让 AI 在审查时只读取改动真正波及到的文件,而不是靠猜测去做全量扫描。 官方文档把这种能力称为 blast-radius analysis,也就是“爆炸半径分析”:当某个文件变更后,工具会沿着调用、继承、依赖和测试链条往外追踪,找出所有可能受影响的代码。
它怎么工作
工具首先用 Tree-sitter 把仓库解析成 AST,并抽取函数、类、导入、调用点、继承关系与测试覆盖等结构信息,再把这些信息存到本地 SQLite 图数据库中。 到了 review 阶段,AI 不再直接读整个项目,而是先查询图谱,拿到一份最小上下文集合,只阅读与当前问题直接相关的文件和节点。
它还支持增量更新。官方说明显示,后续更新只会重新解析发生变化的文件,并通过哈希和依赖追踪来刷新相关节点;在一个约 2,900 文件的项目中,重新索引可以控制在 2 秒以内。 对 monorepo 这类大型仓库来说,这种方式尤其有价值,因为它能从上万文件里缩小到十几个真正需要读取的文件。
支持的平台与工具
code-review-graph 通过 MCP 集成到多种 AI 编码平台中,官方快速开始与平台说明中列出的支持对象包括 Claude Code、Codex、Cursor、Windsurf、Zed、Continue、Kiro、OpenCode、Antigravity、Qwen 和 Qoder。 这意味着它并不局限于某一个 AI 编辑器,而是尽量把“图谱上下文”能力接到不同的 coding agent 或 AI IDE 上。
类型 | 支持的平台/工具 |
|---|---|
官方 AI 编码工具 | Claude Code、Codex、Cursor、Windsurf、Zed、Continue、Kiro |
其他已列出平台 | OpenCode、Antigravity、Qwen、Qoder |
集成方式 | 通过 MCP 接入,在支持的平台中调用图谱能力 |
如果只想给某个平台单独安装,也可以显式指定平台名,例如 code-review-graph install --platform codex、code-review-graph install --platform cursor、code-review-graph install --platform claude-code 或 code-review-graph install --platform kiro。
如何使用
最基础的使用流程很简单:先安装,再给 AI 工具写入 MCP 配置,最后回到具体项目中构建图谱。
pip install code-review-graph
code-review-graph install
cd /path/to/your/project
code-review-graph build
这里有一个非常重要、也很容易写含糊的点:code-review-graph install 不是在项目根目录里执行的“项目初始化命令”,它本质上是一个全局配置命令。 官方文档写得很清楚,这个命令会自动检测你机器上已安装的 AI 编码工具,写入对应的 MCP 配置,并把图谱相关指令注入这些平台的规则配置中;执行完之后还需要重启对应的编辑器或工具。
相对地,code-review-graph build 才是应该在项目根目录中执行的命令。 官方说明是 “Then open your project”,接着让 AI assistant 为“this project”构建 code review graph;同时,工具的忽略文件 .code-review-graphignore 也明确要求放在 repository root,而本地图谱数据则存放在项目中的 .code-review-graph/ 目录里。 换句话说,install 负责把能力接入你的 AI 工具,build 负责对当前仓库真正建图。
为了避免读者混淆,也可以把这两个命令的职责直接对照着写清楚:
命令 | 是否在项目根目录执行 | 作用 |
|---|---|---|
| 否,不要求在项目根目录执行 | 检测本机 AI 工具并写入对应 MCP 配置 |
| 是,需要在目标项目根目录执行 | 为当前仓库建立本地图谱并生成 |
如果编辑器本身不支持 hooks,或者希望图谱在后台持续保持最新,还可以使用 daemon 模式。官方文档提供了 crg-daemon add、crg-daemon start、crg-daemon status 等命令,用来注册多个仓库并自动监听文件变化。
常用命令
除了安装与建图,官方文档还给出了比较完整的 CLI 能力。
命令 | 作用 |
|---|---|
| 自动检测并配置所有支持的平台。 |
| 仅配置指定平台。 |
| 完整解析当前代码库并创建图谱。 |
| 仅对变更文件做增量更新。 |
| 持续监听文件变化并自动更新图谱。 |
| 生成交互式 HTML 图谱,也可导出 GraphML、SVG、Obsidian vault 或 Neo4j Cypher。 |
| 根据社区结构自动生成 Markdown wiki。 |
| 做带风险评分的变更影响分析。 |
在支持 Slash Commands 的工具中,还可以直接用 /code-review-graph:build-graph、/code-review-graph:review-delta 和 /code-review-graph:review-pr 来调用相应工作流。
效果如何
官方基准测试基于 6 个真实开源仓库、13 次提交进行评估,结果显示 graph 模式相对 naive 全量读取,平均可把 Token 消耗降到原来的约八分之一,整体减少 8.2 倍。 从公开数据看,不同仓库的收益并不完全一样,但大部分中大型项目都有比较明显的下降幅度。
项目 | Token 减少倍数 |
|---|---|
Gin | 16.4× |
Flask | 9.1× |
FastAPI | 8.1× |
Next.js | 8.0× |
httpx | 6.9× |
平均 | 8.2× |
它的另一个重点指标是影响分析准确率。官方给出的结果是召回率达到 100%,平均 F1 为 0.54、平均精确率为 0.38。 这说明它在策略上偏保守:宁可多提示一些“可能受影响”的文件,也尽量不漏掉真正会被改动波及的依赖。
指标 | 数值 | 含义 |
|---|---|---|
Recall | 100% | 不漏掉真正受影响的文件 |
F1 | 0.54 | 综合衡量召回率与精确率 |
Precision | 0.38 | 会偏保守,可能多纳入一些候选文件 |
不过,这种方式也不是所有场景都占优。官方明确提到,在体量较小、改动又非常局部的项目中,图谱元数据本身的上下文开销可能反而大于直接读取文件的成本,例如 express 的单文件变更测试中 reduction 只有 0.7x。 所以它最适合的场景,仍然是中大型项目、多文件改动、复杂依赖关系以及高频 AI review 工作流。
适合哪些团队
如果团队已经把 Claude Code、Codex、Cursor 或类似工具纳入日常开发流程,而且项目规模较大、模块关系复杂、PR 评审频繁,那么 code-review-graph 的价值会比较直接。 它本质上不是替代代码审查,而是先帮 AI 把“该读什么”这件事做对,从而让后续的 review、调试、架构分析和 onboarding 都建立在更准确的上下文之上。
对于单人项目、很小的仓库或偶发性的简单改动,它未必总能带来明显收益。 但对于希望系统性降低 AI 编码成本、减少上下文噪声、提升代码审查命中率的团队来说,它已经展示出了相当实用的效果。
在 Google 上继续关注
把 HeyBinyang 添加为 Google 首选来源
如果你愿意继续在 Google 里读到我的更新,可以把这个站点添加为 preferred source,之后更容易在相关内容场景里看到它。
SHARE
分享
分享这篇文章。