寫給前端工程師的 MCP 入門指南
很多前端工程師第一次接觸 MCP,都會有點懵:名字像協定,內容像 Agent,討論裡又總會出現 Tool、Prompt、Resource、Skill。其實沒必要一開始把所有術語都啃下來,只要先抓住一句話:MCP 是讓 AI 能接工具、拿數據、真的做事的一套標準方式。
如果把以前的大模型比作一個只會說話的同事,那接入 MCP 之後,它就可以獲得查系統、調接口、讀檔案的能力了。它不再只是回答問題,而且還可以在授權範圍內去幫你完成一些操作,這也是 MCP 被越來越多 AI 開發工具採用的重要原因之一。
什麼是 MCP
MCP 全稱 Model Context Protocol,是一個開放協定,用來連接 LLM 應用與外部資料來源、工具和系統能力。
如果用前端熟悉的方式理解,HTTP 解決的是瀏覽器如何和伺服器通訊,而 MCP 解決的是 AI 應用如何和工具、資源、上下文通訊。
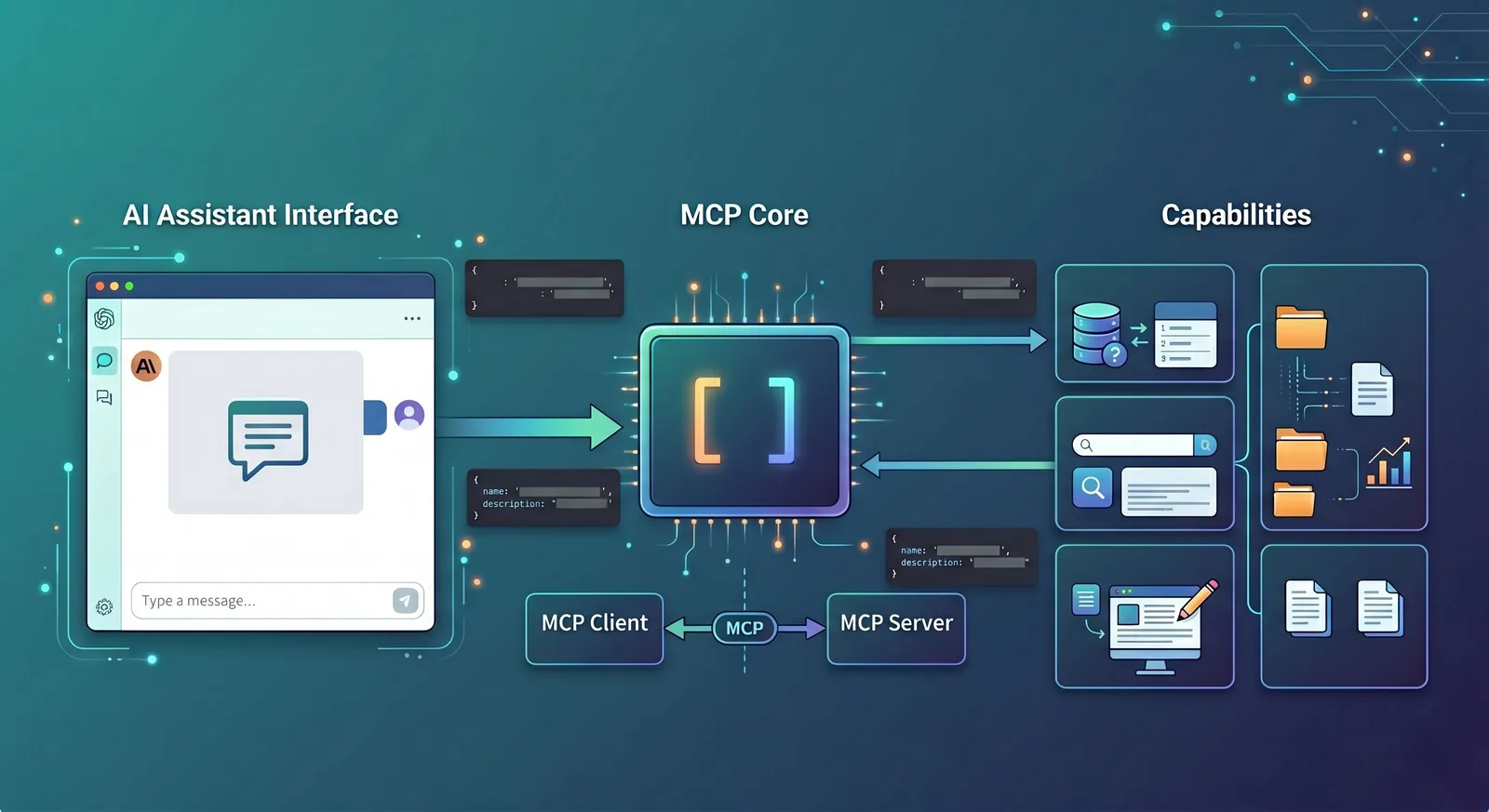
官方架構文件把通訊角色分成 Host、Client 和 Server:Host 是發起連接的 LLM 應用,Client 是宿主 Host 裡的連接器,Server 是工具和上下文能力的提供者。
這個設計和前端熟悉的「宿主應用 + SDK + 服務端」非常接近。你可以把它理解成:Host 負責介面和模型,Client 負責按協定通訊,Server 負責真正提供能力。
先看一個最直觀的例子
假設你做了一個後台系統,右下角放了一個 AI 助手。用戶問它:「今天新增了多少訂單?」
如果沒有 MCP,這個助手通常只能停留在聊天層:要嘛根據訓練資料猜一個結果,要嘛你自己再額外寫一套工具呼叫格式,把資料庫查詢接口和權限邏輯硬接進去。
如果用了 MCP,流程就清晰很多。AI 助手先去問某個 MCP Server:「你這邊有什麼工具?」服務端回傳一組工具列表,比如 get_today_orders、get_order_detail、export_report,每個工具都帶著用途說明和參數 schema。
接著模型看到用戶的問題後,選擇呼叫 get_today_orders。服務端查完資料庫,把結果回傳給 AI,再由 AI 用自然語言回覆「今天新增 128 單」。這就是 MCP 最典型的使用方式:先發現工具,再呼叫工具,再把結果組織成用戶能理解的話。
Host、Client、Server 到底分別是誰
這三個詞經常一起出現,但一點都不難。可以拿「外送平台」來類比:Host 像外送 App,Client 像 App 裡的排程系統,Server 像真正出餐的商家。
放到 MCP 裡:
Host 是你直接看到的 AI 應用,比如 Claude Desktop、Claude Code、某個 IDE 外掛,或者你自己做的 Web AI 頁面。
Client 是 Host 內部負責按 MCP 協定和外界通訊的那一層。
Server 是真正提供能力的一方,比如日誌服務、檔案系統適配器、資料庫查詢服務、GitHub 工具服務。
舉個開發場景。假設你在 VS Code 裡用 AI 程式設計助手,讓它「幫我看看目前專案裡哪個接口超時最多」。此時 VS Code 裡的 AI 助手是 Host,助手內部負責協定通訊的是 Client,能訪問日誌、程式碼倉庫、監控平台的那些能力提供方,就是 MCP Server。
Tool 是你最先該理解的東西
MCP 裡最重要的東西不是 Prompt,也不是 Resource,而是 Tool。因為絕大多數「AI 真正開始做事」的體驗,都是從 Tool 開始的。
你可以把 Tool 理解成一個「給 AI 用的接口」。它通常會包含三樣東西:工具名、用途說明,以及一份參數 schema,也就是參數的結構定義。
比如一個天氣工具,可能長這樣:
name:
get_weatherdescription: 查詢某個城市目前天氣
input schema:
location,類型是 string,而且必填。
當客戶端呼叫它時,會透過 tools/call 這類請求,把工具名和參數一起發過去。官方工具規範和範例都採用了這種模式。
再舉一個更貼近前端的例子。你做了一個內容後台,可以給 AI 助手接三個工具:
search_articles:按關鍵字查文章。get_article_detail:查某篇文章詳情。publish_article:發佈文章。
這樣用戶說「把標題裡帶 MCP 的草稿找出來並發佈最新一篇」,AI 就有機會先查列表,再取詳情,再呼叫發佈接口。你會發現,這其實就是把一組後台 API 暴露給模型去組合呼叫。
為什麼 schema 很重要
很多人第一次看 MCP,會覺得「工具名 + 描述」就夠了,為什麼還非得寫 schema。原因很簡單:模型不是靠猜來調工具的,它需要一個清晰的參數契約。
比如你寫了一個 create_user 工具,如果沒有 schema,模型可能不知道 email 是不是必填,也不知道 age 到底應該傳數字還是字串。加上 schema 之後,模型和客戶端都能明確知道怎麼建構參數;前端也可以基於這些結構,直接產生除錯表單或型別定義,這和看 Swagger 文件聯調接口的體驗非常接近。
這也是為什麼 MCP 對前端工程師很友好。它不是一種完全靠 prompt 猜測的接入方式,而是盡量把工具能力結構化、明確化、可驗證化。
一次完整呼叫到底怎麼發生
還是用一個簡單場景說明:用戶在 AI 助手里輸入「幫我查一下今天有多少新註冊用戶」。
第一步,Host 先知道自己連接了哪些 MCP Server,比如一個 analytics server。這個 server 對外提供了 get_signup_count 工具。
第二步,Client 透過 tools/list 拿到工具定義,知道這個工具需要一個 date 參數,類型是字串。
第三步,模型判斷這個問題需要呼叫 get_signup_count,於是客戶端發一個 tools/call 請求,參數可能是 { "date": "2026-05-03" }。
第四步,Server 去查資料庫或分析服務,回傳結果,比如 356。然後 Host 再把這個結果組織成面向用戶的話術:「今天新增註冊用戶 356 人。」
這個過程最關鍵的點在於:模型並不直接操作資料庫,它始終是透過一個被明確定義好的工具來間接完成動作。這樣權限、安全、稽核和錯誤處理都更容易做。
Resource 和 Prompt,只需要先知道是幹什麼的
除了 Tool,MCP 裡還經常提到 Resource 和 Prompt。它們確實有用,但入門階段不用學很深。
Resource 更像「給模型看的材料」,不一定是可執行動作。比如最近 1 小時的錯誤日誌、目前打開檔案的內容、某個專案的 README,或者資料庫表結構說明,這些都可以作為 Resource 提供給模型參考。
比如用戶問「為什麼這個接口總是超時」,AI 可能不需要立刻呼叫很多工具,而是先讀取一份日誌 Resource 和一段程式碼 Resource,然後再分析問題。官方關於 prompts 和 resources 的範例就展示了這種把日誌和程式碼檔案一起提供給模型的用法。
Prompt 則更像可重複使用的任務模板。比如提供一個 git-commit prompt,輸入程式碼改動,輸出一條風格統一的提交訊息;也可以有一個 explain-code prompt,專門用於解釋某段程式碼。
如果只想記一個最簡單的區別,可以這麼理解:Tool 是「能做事的按鈕」,Resource 是「給模型看的資料」,Prompt 是「常用工作模板」。
為什麼前端會明顯受益
前端受益最大的地方,不是「也能寫協定」,而是互動方式會被改變。
以前頁面上的 AI 助手通常只有一個輸入框,能做的事情很有限。現在如果背後接了 MCP,前端就可以把很多東西明確展示出來,比如目前 AI 擁有哪些工具、這次準備呼叫什麼工具、為什麼要申請某個權限、呼叫結果是什麼、哪一步失敗了。
這會讓 AI 產品更像一個「可觀察、可控制的工作台」,而不只是一個黑箱聊天框。尤其在後台系統、IDE、內部工具這類場景裡,用戶通常更願意看到 AI 到底做了什麼,而不是只收到一句神秘的答案。
再舉個貼近前端工作流程的例子。你做一個日誌分析頁面,用戶點中一條錯誤日誌後,右側 AI 助手自動拿到這些 context:目前服務名稱、錯誤時間範圍、選中的日誌片段、目前倉庫分支名稱。
然後用戶只說一句:「幫我分析一下原因。」此時 AI 可以先讀取日誌 Resource,再呼叫 search_recent_deploys、get_error_rate 這類 Tool,最後回傳一段更可靠的分析。這個體驗的關鍵,不在於模型更聰明,而在於前端把介面狀態轉成了模型可用的上下文。
MCP 現在在什麼位置上
25-26 年以來圈子裡討論得最多的,是各種 Skill、Workflow、Agent 編排,MCP 的熱度看起來確實不如剛出來那會兒高。但從工程角度看,Skill 再火,它的背後,很多時候還是 MCP 在幹活。
用一個具體例子就很清楚:
Skill 像一套「客服處理退款」的話術和流程,先確認訂單,再查支付狀態,再核對風控,最後給出處理結果。
MCP 則像「客服系統背後的統一接口層」,幫你連上訂單服務、支付服務、風控服務,讓每一步「去查一下」都有對應的工具可以調。
換成開發場景也是一樣:
Skill 可以定義「如何做一次程式碼審查」,先看 diff,再看測試,再看錯誤日誌,最後產生審查意見。
真正去拉 diff、查 CI、讀日誌的動作,通常是透過 MCP 暴露出來的工具來完成;Skill 負責的是「按什麼順序用哪些工具」,而 MCP 負責「這些工具怎麼連、怎麼調、怎麼拿結果」。
所以現在的格局更像是:對外宣傳和產品賣點更多在講 Skill 有多聰明、流程多自動化;但在底層、在程式碼裡,MCP 依然是那層穩定的「接線板」,把模型和各種業務系統、安全閘道、資料庫、日誌平台連在一起。
它的名字也許沒有 Skill 那麼熱,但只要你在做的是「讓 AI 真正作業系統、查真實資料」的產品,協定層這塊就必須有人扛,而 MCP 正是在很多專案裡扮演這個安靜但關鍵的角色。
MCP 和 Skill 的區別
如果只用一句話區分:MCP 解決「工具怎麼接」,Skill 解決「任務怎麼做」。
還是拿「程式碼審查助手」舉例。
如果現在關心的是:怎麼讓 AI 訪問 Git diff、怎麼查 CI 結果、怎麼讀 lint 報告,那你面對的是 MCP 問題,因為這些都屬於「把能力接進來」。
但如果關心的是:程式碼審查先看什麼、哪些風險要優先提示、輸出結果按什麼格式寫、什麼情況下要建議補測試,那這更像 Skill 問題,因為它是在定義「這件事該怎麼做」。
現實裡兩者通常會配合出現。MCP 負責連 Git、CI、日誌平台,Skill 負責固化「程式碼審查流程」;但作為入門理解,只要先把這條邊界分清楚就夠了。
它為什麼值得學
MCP 值得學,不是因為它是一個新名詞,而是因為它把 AI 產品開發裡最容易混亂的一層做了標準化:工具發現、參數描述、上下文傳遞和執行呼叫。
當這層被標準化之後,前端工程師就不必每做一個新 AI 產品,都重新發明一套「模型如何接後端能力」的協定。
更重要的是,這種標準化會讓前端的職責邊界變得更有意思。頁面不再只是輸入輸出的容器,而會逐步成為 AI 行為的控制台:展示工具、解釋狀態、呈現計劃、申請授權、回饋結果。
這讓前端工程師在 AI 產品裡不只是「接個 SDK」,而是真正參與定義人機協作的互動方式。
結語
如果只用一句話概括,MCP 的價值就是:它讓 AI 應用第一次擁有了一層相對統一、可重複使用、工程化的「外部能力接入層」。
對於前端工程師,理解它並不需要先成為 AI 專家,只需要把它看成一種新的協定層,一種讓介面、模型和業務系統能夠協同工作的標準連接方式。
在 Google 上持續關注
把 HeyBinyang 加入 Google 首選來源
如果你希望之後在 Google 上更容易看到我的更新,可以把這個站點加入 preferred source,讓它在相關閱讀情境裡更容易被找到。
SHARE
分享
分享這篇文章。