프론트엔드 개발자를 위한 MCP 입문 가이드
많은 프론트엔드 엔지니어들이 MCP를 처음 접하면 다소 혼란스러워합니다. 이름은 프로토콜 같고, 내용은 Agent 같으며, 논의에서는 항상 Tool, Prompt, Resource, Skill이 등장합니다. 사실 처음부터 모든 용어를 이해할 필요는 없습니다. 한 문장만 기억하세요: MCP는 AI가 도구를 사용하고, 데이터를 가져오고, 실제로 작업을 수행할 수 있게 해주는 표준 방식입니다.
예전의 대형 언어 모델을 말만 할 줄 아는 동료에 비유한다면, MCP를 도입한 후에는 시스템 조회, 인터페이스 호출, 파일 읽기 등의 능력을 갖출 수 있습니다. 더 이상 질문에 답변만 하는 것이 아니라, 권한 범위 내에서 사용자를 대신해 일부 작업을 수행할 수 있습니다. 이것이 MCP가 점점 더 많은 AI 개발 도구에 채택되는 중요한 이유 중 하나입니다.
MCP란 무엇인가
MCP는 Model Context Protocol의 약자로, LLM 애플리케이션과 외부 데이터 소스, 도구, 시스템 기능을 연결하는 개방형 프로토콜입니다.
프론트엔드에 익숙한 방식으로 이해하자면, HTTP는 브라우저와 서버 간의 통신을 해결하는 반면, MCP는 AI 애플리케이션이 도구, 리소스, 컨텍스트와 통신하는 방법을 해결합니다.
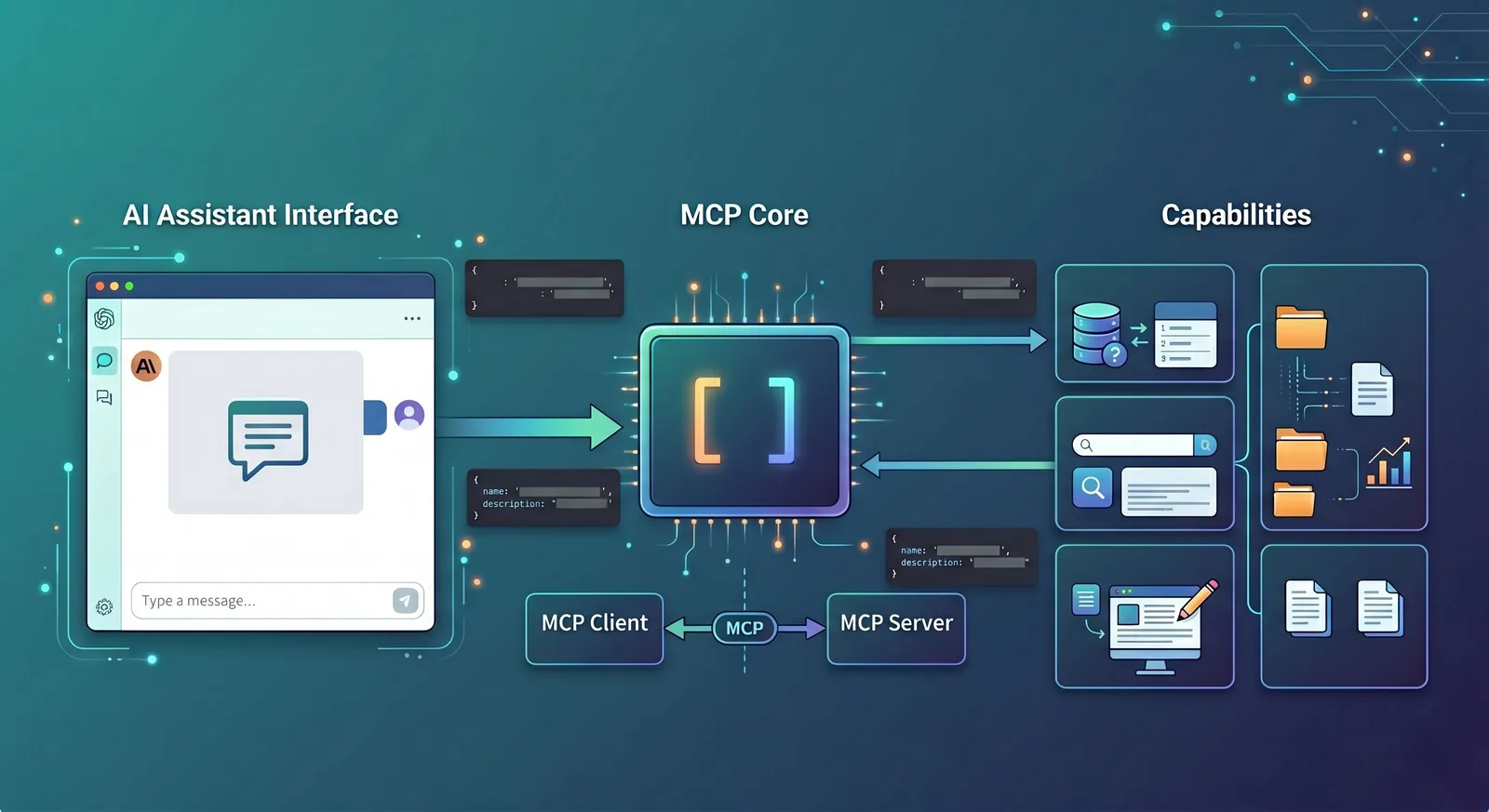
공식 아키텍처 문서에서는 통신 역할을 Host, Client, Server로 구분합니다. Host는 연결을 시작하는 LLM 애플리케이션, Client는 Host 내부의 커넥터, Server는 도구와 컨텍스트 기능의 제공자입니다.
이 설계는 프론트엔드에 익숙한 '호스트 앱 + SDK + 서버'와 매우 유사합니다. 이해하기 쉽게 말하면, Host는 UI와 모델을 담당하고, Client는 프로토콜에 따라 통신하며, Server는 실제 기능을 제공합니다.
가장 직관적인 예를 먼저 살펴보자
관리자 시스템을 만들었고, 오른쪽 하단에 AI 어시스턴트를 배치했다고 가정해 봅시다. 사용자가 "오늘 신규 주문이 몇 개인가요?"라고 묻습니다.
MCP가 없다면, 이 어시스턴트는 보통 채팅 수준에 머물게 됩니다. 훈련 데이터를 기반으로 결과를 추측하거나, 사용자가 직접 추가적인 도구 호출 형식을 작성하여 데이터베이스 쿼리 인터페이스와 권한 로직을 하드코딩해야 합니다.
MCP를 사용하면 프로세스가 훨씬 명확해집니다. AI 어시스턴트는 먼저 특정 MCP Server에 "어떤 도구가 있습니까?"라고 묻습니다. 서버는 도구 목록을 반환합니다. 예를 들어 get_today_orders, get_order_detail, export_report 등이며, 각 도구는 용도 설명과 파라미터 스키마를 포함합니다.
그런 다음 모델은 사용자의 질문을 보고 get_today_orders를 호출하기로 결정합니다. 서버가 데이터베이스를 조회한 후 결과를 AI에 반환하고, AI는 자연어로 "오늘 신규 주문 128건입니다"라고 응답합니다. 이것이 MCP의 가장 일반적인 사용 방식입니다: 먼저 도구를 발견하고, 도구를 호출한 다음, 결과를 사용자가 이해할 수 있는 말로 구성하는 것입니다.
Host, Client, Server는 각각 무엇인가
이 세 용어는 자주 함께 등장하지만 전혀 어렵지 않습니다. '배달 플랫폼'에 비유해 보겠습니다. Host는 배달 앱, Client는 앱 내부의 배차 시스템, Server는 실제로 음식을 만드는 가게와 같습니다.
MCP에 적용하면:
Host는 사용자가 직접 보는 AI 애플리케이션입니다. 예: Claude Desktop, Claude Code, 특정 IDE 플러그인, 또는 직접 만든 웹 AI 페이지.
Client는 Host 내부에서 MCP 프로토콜에 따라 외부와 통신하는 계층입니다.
Server는 실제로 기능을 제공하는 주체입니다. 예: 로그 서비스, 파일 시스템 어댑터, 데이터베이스 쿼리 서비스, GitHub 도구 서비스.
개발 시나리오를 들어보겠습니다. VS Code에서 AI 코딩 어시스턴트를 사용하여 "현재 프로젝트에서 어떤 인터페이스가 가장 많이 타임아웃되는지 알려줘"라고 요청한다고 가정해 봅시다. 이때 VS Code의 AI 어시스턴트가 Host이고, 어시스턴트 내부에서 프로토콜 통신을 담당하는 부분이 Client이며, 로그, 코드 저장소, 모니터링 플랫폼에 접근할 수 있는 기능 제공자들이 MCP Server입니다.
Tool이 가장 먼저 이해해야 할 개념이다
MCP에서 가장 중요한 것은 Prompt도 Resource도 아닌 Tool입니다. 왜냐하면 대부분의 'AI가 실제로 작업을 시작하는' 경험은 Tool에서 시작되기 때문입니다.
Tool은 'AI가 사용하는 인터페이스'라고 생각하면 됩니다. 일반적으로 세 가지 요소를 포함합니다: 도구 이름, 용도 설명, 그리고 파라미터 스키마(파라미터의 구조 정의).
예를 들어, 날씨 도구는 다음과 같을 수 있습니다:
name:
get_weatherdescription: 특정 도시의 현재 날씨 조회
input schema:
location, 타입은 string이며 필수.
클라이언트가 이를 호출할 때는 tools/call 같은 요청을 통해 도구 이름과 파라미터를 함께 보냅니다. 공식 도구 규격과 예제는 모두 이 패턴을 따릅니다.
프론트엔드에 더 가까운 예를 들어보겠습니다. 콘텐츠 관리 시스템을 만들고 AI 어시스턴트에 세 가지 도구를 연결했다고 가정해 봅시다:
search_articles: 키워드로 기사 검색.get_article_detail: 특정 기사 상세 조회.publish_article: 기사 발행.
이렇게 하면 사용자가 "제목에 MCP가 포함된 초안을 찾아서 최신 글을 발행해줘"라고 말하면 AI는 먼저 목록을 조회하고, 상세 정보를 가져온 후, 발행 인터페이스를 호출할 수 있습니다. 이는 결국 백엔드 API 집합을 모델이 조합하여 호출할 수 있도록 노출하는 것임을 알 수 있습니다.
스키마가 중요한 이유
많은 사람들이 MCP를 처음 볼 때 '도구 이름 + 설명'만 있으면 충분하다고 생각합니다. 그런데 왜 스키마를 작성해야 할까요? 이유는 간단합니다. 모델은 추측으로 도구를 호출하는 것이 아니라 명확한 파라미터 계약이 필요하기 때문입니다.
예를 들어 create_user 도구를 작성했는데 스키마가 없으면 모델은 email이 필수인지, age에 숫자를 전달해야 하는지 문자열을 전달해야 하는지 알 수 없습니다. 스키마를 추가하면 모델과 클라이언트 모두 파라미터를 구성하는 방법을 명확히 알 수 있습니다. 프론트엔드에서도 이 구조를 기반으로 디버깅 폼이나 타입 정의를 직접 생성할 수 있어 Swagger 문서로 인터페이스를 연동하는 경험과 매우 유사합니다.
이것이 MCP가 프론트엔드 엔지니어에게 친숙한 이유이기도 합니다. 전적으로 프롬프트 추측에 의존하는 접근 방식이 아니라, 도구 기능을 구조화하고 명확화하며 검증 가능하게 만듭니다.
전체 호출은 실제로 어떻게 이루어지는가
간단한 시나리오로 설명하겠습니다. 사용자가 AI 어시스턴트에 "오늘 신규 가입자가 몇 명인지 확인해줘"라고 입력합니다.
첫 번째 단계, Host는 자신이 연결된 MCP Server를 확인합니다. 예를 들어 analytics server가 있습니다. 이 서버는 외부에 get_signup_count 도구를 제공합니다.
두 번째 단계, Client는 tools/list를 통해 도구 정의를 가져와서 이 도구가 date 파라미터(타입은 string)를 필요로 한다는 것을 알게 됩니다.
세 번째 단계, 모델은 이 질문에 get_signup_count를 호출해야 한다고 판단하고, 클라이언트가 tools/call 요청을 보냅니다. 파라미터는 아마 { "date": "2026-05-03" }일 것입니다.
네 번째 단계, Server가 데이터베이스나 분석 서비스를 조회하여 결과(예: 356)를 반환합니다. 그러면 Host가 이 결과를 사용자에게 전달할 말투로 구성합니다: "오늘 신규 가입자는 356명입니다."
이 과정에서 가장 중요한 점은 모델이 데이터베이스를 직접 조작하지 않고, 항상 명확히 정의된 도구를 통해 간접적으로 작업을 수행한다는 것입니다. 이렇게 하면 권한, 보안, 감사, 오류 처리가 훨씬 쉬워집니다.
Resource와 Prompt는 용도만 알아도 충분하다
Tool 외에도 MCP에서는 Resource와 Prompt가 자주 언급됩니다. 실제로 유용하지만, 입문 단계에서는 깊이 배울 필요가 없습니다.
Resource는 '모델이 참고할 자료'에 가깝습니다. 실행 가능한 동작이 아닐 수도 있습니다. 예를 들어 최근 1시간 동안의 오류 로그, 현재 열려 있는 파일의 내용, 특정 프로젝트의 README, 데이터베이스 테이블 구조 설명 등이 Resource로 모델에 제공될 수 있습니다.
예를 들어 사용자가 "이 인터페이스가 왜 자주 타임아웃되나요?"라고 물으면 AI는 많은 도구를 즉시 호출할 필요 없이 먼저 로그 Resource와 코드 Resource를 읽고 문제를 분석할 수 있습니다. 공식 문서의 prompts와 resources 예제는 로그와 코드 파일을 함께 모델에 제공하는 이러한 사용법을 보여줍니다.
Prompt는 재사용 가능한 작업 템플릿에 가깝습니다. 예를 들어 git-commit prompt를 제공하여 코드 변경 사항을 입력하면 일관된 스타일의 커밋 메시지를 출력하거나, explain-code prompt를 제공하여 특정 코드를 설명하는 데 사용할 수 있습니다.
가장 간단한 차이점만 기억하고 싶다면 이렇게 이해할 수 있습니다. Tool은 '일을 할 수 있는 버튼', Resource는 '모델이 볼 자료', Prompt는 '자주 사용하는 작업 템플릿'입니다.
프론트엔드가 명확히 이점을 얻는 이유
프론트엔드가 가장 크게 이점을 얻는 부분은 '프로토콜을 작성할 수 있다'는 것이 아니라, 상호작용 방식이 변화한다는 점입니다.
이전에는 페이지의 AI 어시스턴트가 보통 입력창 하나뿐이어서 할 수 있는 일이 제한적이었습니다. 이제 뒤에 MCP가 연결되어 있으면 프론트엔드에서 많은 것을 명시적으로 표시할 수 있습니다. 예를 들어 AI가 현재 어떤 도구를 가지고 있는지, 이번에 어떤 도구를 호출할 예정인지, 왜 특정 권한을 요청하는지, 호출 결과는 무엇인지, 어떤 단계에서 실패했는지 등입니다.
이로 인해 AI 제품은 '관찰 가능하고 제어 가능한 작업대'처럼 되어, 단순한 블랙박스 채팅창이 아닙니다. 특히 관리 시스템, IDE, 내부 도구와 같은 시나리오에서 사용자는 신비한 답변 하나만 받는 것이 아니라 AI가 실제로 무엇을 했는지 보기를 원합니다.
프론트엔드 워크플로우에 가까운 예를 들어보겠습니다. 로그 분석 페이지를 만들었고, 사용자가 오류 로그 하나를 클릭하면 오른쪽의 AI 어시스턴트가 자동으로 다음 컨텍스트를 가져옵니다: 현재 서비스 이름, 오류 시간 범위, 선택된 로그 조각, 현재 저장소 브랜치 이름.
그런 다음 사용자는 단순히 "원인을 분석해줘"라고 말합니다. 그러면 AI는 먼저 로그 Resource를 읽고, search_recent_deploys, get_error_rate 같은 Tool을 호출한 후, 더 신뢰할 수 있는 분석을 반환합니다. 이 경험의 핵심은 모델이 더 똑똑해졌기 때문이 아니라, 프론트엔드가 UI 상태를 모델이 사용할 수 있는 컨텍스트로 변환했기 때문입니다.
MCP의 현재 위치
25-26년 이후 업계에서 가장 많이 논의되는 것은 다양한 Skill, Workflow, Agent 오케스트레이션입니다. MCP의 인기는 처음 나왔을 때만큼 높지 않아 보입니다. 그러나 엔지니어링 관점에서 보면, Skill이 아무리 인기를 끌더라도 그 뒤에는 여전히 MCP가 작업을 수행하는 경우가 많습니다.
구체적인 예를 들면 명확합니다:
Skill은 '고객센터의 환불 처리'를 위한 스크립트와 절차와 같습니다. 먼저 주문을 확인하고, 결제 상태를 조회하고, 리스크 검증을 한 후 최종 결과를 제공합니다.
MCP는 '고객센터 시스템 뒤의 통합 인터페이스 계층'과 같아서, 주문 서비스, 결제 서비스, 리스크 관리 서비스를 연결하여 각 단계의 '조회'에 해당하는 도구를 제공합니다.
개발 시나리오로 바꿔도 마찬가지입니다:
Skill은 '코드 리뷰를 어떻게 수행할지' 정의할 수 있습니다. 먼저 diff를 보고, 테스트를 보고, 오류 로그를 본 후 리뷰 의견을 생성합니다.
실제로 diff를 가져오고, CI를 확인하고, 로그를 읽는 동작은 일반적으로 MCP를 통해 노출된 도구로 수행됩니다. Skill은 '어떤 순서로 어떤 도구를 사용할지'를 담당하고, MCP는 '이 도구들을 어떻게 연결하고, 호출하고, 결과를 가져올지'를 담당합니다.
따라서 현재 구도는 이렇습니다: 외부 홍보와 제품 마케팅 포인트는 Skill이 얼마나 똑똑한지, 프로세스가 얼마나 자동화되었는지에 더 초점을 맞추고 있습니다. 그러나 내부, 코드 속에서는 MCP가 여전히 안정적인 '연결판' 역할을 하며, 모델과 다양한 비즈니스 시스템, 보안 게이트웨이, 데이터베이스, 로그 플랫폼을 연결합니다.
Skill만큼 이름이 뜨겁지 않을 수 있지만, 'AI가 실제로 시스템을 운영하고 실제 데이터를 조회하는' 제품을 만들고 있다면 프로토콜 계층은 반드시 누군가가 담당해야 합니다. 그리고 MCP는 많은 프로젝트에서 이 조용하지만 중요한 역할을 수행하고 있습니다.
MCP와 Skill의 차이점
한 문장으로 구분하자면, MCP는 '도구를 어떻게 연결할지'를 해결하고, Skill은 '작업을 어떻게 수행할지'를 해결합니다.
다시 '코드 리뷰 어시스턴트'를 예로 들어보겠습니다.
만약 지금 관심 있는 것이 AI가 Git diff에 어떻게 접근하는지, CI 결과를 어떻게 조회하는지, lint 보고서를 어떻게 읽는지라면, 이는 MCP 문제입니다. 왜냐하면 이것들은 모두 '기능을 연결하는 것'에 속하기 때문입니다.
하지만 관심 있는 것이 코드 리뷰에서 무엇을 먼저 봐야 하는지, 어떤 리스크를 우선적으로 알려야 하는지, 출력 결과를 어떤 형식으로 작성해야 하는지, 어떤 상황에서 테스트 추가를 제안해야 하는지라면, 이는 Skill 문제에 더 가깝습니다. 왜냐하면 '이 작업을 어떻게 수행할지'를 정의하기 때문입니다.
현실에서는 둘이 함께 사용되는 경우가 많습니다. MCP는 Git, CI, 로그 플랫폼을 연결하고, Skill은 '코드 리뷰 프로세스'를 고정합니다. 하지만 입문 단계에서는 이 경계선만 구분할 수 있으면 충분합니다.
왜 배울 가치가 있는가
MCP를 배울 가치가 있는 이유는 새로운 용어이기 때문이 아니라, AI 제품 개발에서 가장 혼란스럽기 쉬운 계층을 표준화했기 때문입니다: 도구 발견, 파라미터 설명, 컨텍스트 전달 및 실행 호출.
이 계층이 표준화되면 프론트엔드 엔지니어는 새로운 AI 제품을 만들 때마다 '모델이 백엔드 기능에 어떻게 연결될지'에 대한 프로토콜을 다시 발명할 필요가 없습니다.
더 중요한 것은, 이러한 표준화로 인해 프론트엔드의 역할 경계가 더 흥미로워진다는 점입니다. 페이지는 더 이상 단순한 입출력 컨테이너가 아니라 점차 AI 행동의 콘솔이 됩니다: 도구 표시, 상태 설명, 계획 제시, 권한 요청, 결과 피드백.
이를 통해 프론트엔드 엔지니어는 AI 제품에서 단순히 'SDK를 연결'하는 수준을 넘어, 인간과 AI의 협업 방식 정의에 실제로 참여하게 됩니다.
맺음말
한 문장으로 요약하자면, MCP의 가치는 AI 애플리케이션이 처음으로 비교적 통일되고, 재사용 가능하며, 엔지니어링된 '외부 기능 접근 계층'을 갖게 되었다는 점입니다.
프론트엔드 엔지니어에게 이를 이해하기 위해 먼저 AI 전문가가 될 필요는 없습니다. 단지 새로운 프로토콜 계층, 즉 UI, 모델, 비즈니스 시스템이 함께 작동할 수 있는 표준 연결 방식으로 보면 됩니다.
Google에서 팔로우
HeyBinyang을 Google 선호 소스로 추가
Google에서 내 업데이트를 더 쉽게 찾고 싶다면 이 사이트를 선호 소스로 표시할 수 있습니다.
공유
공유
이 글을 공유합니다.