code-review-graph : pour des revues de code IA plus précises et moins gourmandes en tokens
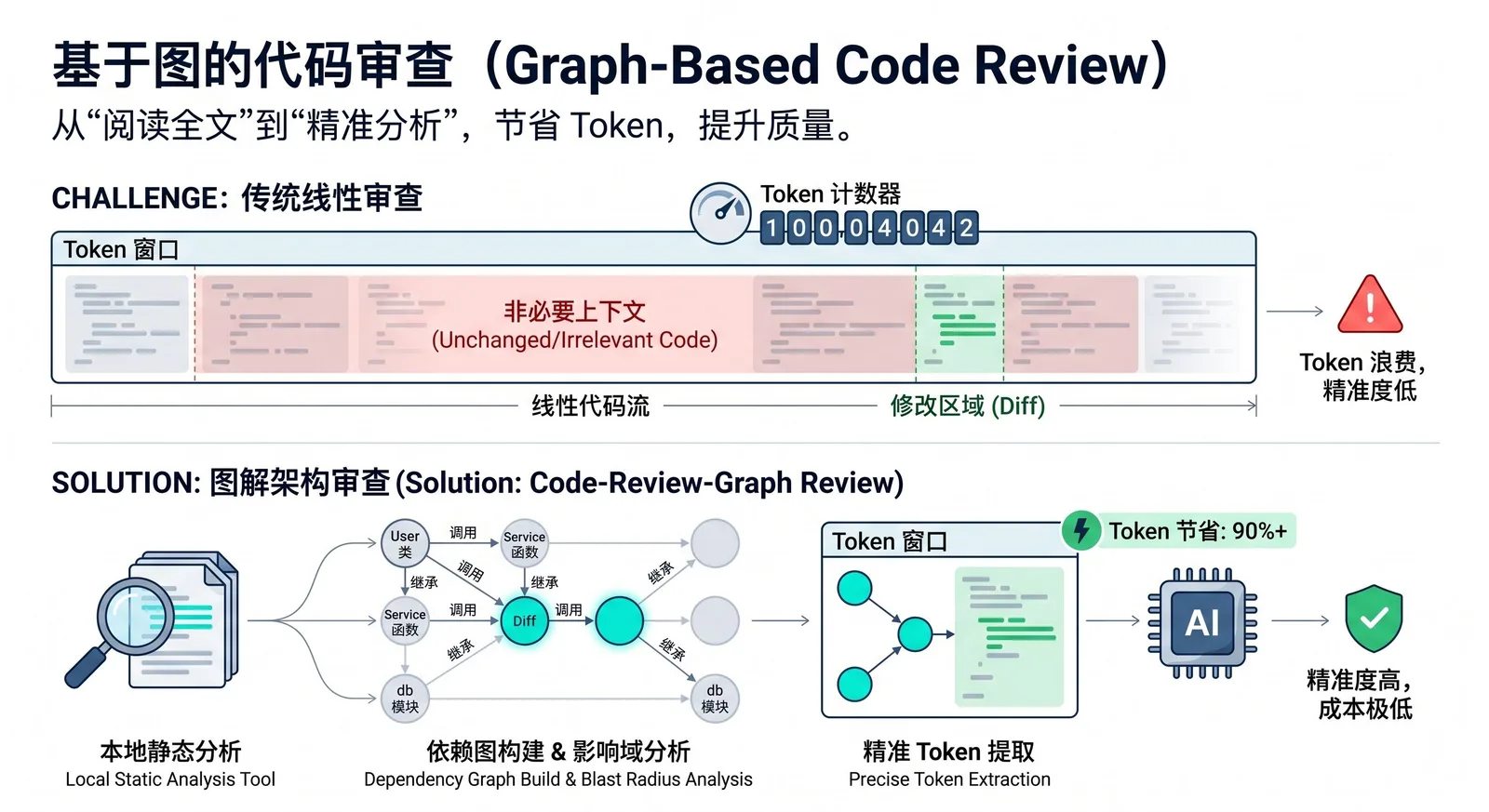
code-review-graph est un outil open source pour les assistants de codage IA. Il construit d'abord localement un « graphe de connaissances structuré » du dépôt, puis fournit à l'IA le contexte vraiment pertinent, évitant ainsi de scanner l'intégralité du dépôt à chaque tâche. Il est basé sur Tree-sitter pour analyser l'AST, organise les fonctions, classes, imports, relations d'appel et relations de test en une structure de graphe, puis les fournit via MCP à des outils comme Claude Code, Codex, Cursor, etc.
Quels problèmes résout-il ?
Actuellement, de nombreux outils de codage IA, lors de la révision de code, de la détermination de la portée de l'impact ou de la compréhension des modifications, lisent à plusieurs reprises l'ensemble du code source, ce qui entraîne un gaspillage important de tokens et une augmentation des coûts. Dans un dépôt contenant des centaines de fichiers, même si une seule fonction est modifiée, l'IA peut avoir besoin de scanner à nouveau de nombreux fichiers non pertinents, entraînant un ralentissement, une augmentation du bruit contextuel et une hausse des dépenses.
L'approche de code-review-graph consiste à modéliser à l'avance les « relations de dépendance du code », afin que l'IA, lors de la révision, ne lise que les fichiers réellement impactés par les modifications, plutôt que de deviner et d'effectuer une analyse complète. La documentation officielle appelle cette capacité « blast-radius analysis », c'est-à-dire « analyse du rayon d'explosion » : lorsqu'un fichier change, l'outil suit les chaînes d'appel, d'héritage, de dépendance et de test pour détecter tout le code potentiellement affecté.
Comment ça marche ?
L'outil commence par analyser le dépôt en AST avec Tree-sitter, extrait des informations structurelles telles que les fonctions, les classes, les imports, les points d'appel, les relations d'héritage et la couverture de test, puis stocke ces informations dans une base de données graphique SQLite locale. Lors de la phase de review, l'IA ne lit plus directement l'ensemble du projet, mais interroge d'abord le graphe pour obtenir un ensemble de contexte minimal, lisant uniquement les fichiers et nœuds directement liés au problème actuel.
Il prend également en charge les mises à jour incrémentielles. Selon la documentation officielle, les mises à jour ultérieures ne ré-analysent que les fichiers modifiés et actualisent les nœuds concernés via le hachage et le suivi des dépendances ; dans un projet d'environ 2 900 fichiers, la réindexation peut être effectuée en moins de 2 secondes. Pour les grands dépôts comme les monorepos, cette approche est particulièrement précieuse, car elle peut réduire des dizaines de milliers de fichiers à seulement une douzaine de fichiers réellement nécessaires à lire.
Plateformes et outils pris en charge
code-review-graph s'intègre via MCP à diverses plateformes de codage IA. Le guide de démarrage rapide officiel et la documentation sur les plateformes listent les cibles prises en charge, notamment Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro, OpenCode, Antigravity, Qwen et Qoder. Cela signifie qu'il ne se limite pas à un seul éditeur IA, mais cherche à connecter la capacité de « contexte de graphe » à différents agents de codage ou IDE IA.
Type | Plateforme/outil pris en charge |
|---|---|
Outils de codage IA officiels | Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro |
Autres plateformes listées | OpenCode, Antigravity, Qwen, Qoder |
Méthode d'intégration | Connecté via MCP, permet d'invoquer les capacités du graphe sur les plateformes prises en charge |
Si vous souhaitez installer uniquement pour une plateforme spécifique, vous pouvez explicitement spécifier le nom de la plateforme, par exemple code-review-graph install --platform codex, code-review-graph install --platform cursor, code-review-graph install --platform claude-code ou code-review-graph install --platform kiro.
Comment l'utiliser
Le flux d'utilisation de base est simple : installez d'abord, puis écrivez la configuration MCP dans l'outil IA, et enfin revenez dans le projet spécifique pour construire le graphe.
pip install code-review-graph
code-review-graph install
cd /path/to/your/project
code-review-graph build
Il y a un point très important et facile à confondre : code-review-graph install n'est pas une « commande d'initialisation de projet » exécutée dans le répertoire racine du projet ; c'est essentiellement une commande de configuration globale. La documentation officielle précise clairement que cette commande détecte automatiquement les outils de codage IA installés sur votre machine, écrit la configuration MCP correspondante et injecte les instructions liées au graphe dans les configurations de règles de ces plateformes ; après l'exécution, il peut être nécessaire de redémarrer l'éditeur ou l'outil correspondant.
En revanche, code-review-graph build est la commande qui doit être exécutée dans le répertoire racine du projet. La documentation officielle dit : « Then open your project », puis demande à l'assistant IA de construire le code review graph pour « this project » ; de plus, le fichier d'ignorance .code-review-graphignore doit être placé à la racine du dépôt, et les données locales du graphe sont stockées dans le répertoire .code-review-graph/ du projet. En d'autres termes, install connecte la capacité à votre outil IA, tandis que build construit réellement le graphe pour le dépôt actuel.
Pour éviter toute confusion chez les lecteurs, on peut aussi clarifier directement les responsabilités de ces deux commandes en les comparant :
Commande | Exécuté dans le répertoire racine du projet ? | Rôle |
|---|---|---|
| Non, pas exigé dans le répertoire racine du projet | Détecte les outils IA locaux et écrit la configuration MCP correspondante |
| Oui, doit être exécuté dans le répertoire racine du projet cible | Construit le graphe local pour le dépôt actuel et génère les données dans .code-review-graph/ |
Si l'éditeur ne prend pas en charge les hooks, ou si l'on souhaite que le graphe reste constamment à jour en arrière-plan, on peut également utiliser le mode daemon. La documentation officielle fournit des commandes telles que crg-daemon add, crg-daemon start, crg-daemon status, pour enregistrer plusieurs dépôts et surveiller automatiquement les modifications de fichiers.
Commandes courantes
Outre l'installation et la construction du graphe, la documentation officielle présente également des capacités CLI assez complètes.
Commande | Rôle |
|---|---|
| Détecte et configure automatiquement toutes les plateformes prises en charge. |
| Configure uniquement la plateforme spécifiée. |
| Analyse complètement le dépôt actuel et crée le graphe. |
| Effectue une mise à jour incrémentielle uniquement sur les fichiers modifiés. |
| Surveille en continu les modifications de fichiers et met à jour automatiquement le graphe. |
| Génère un graphe HTML interactif, et peut également exporter en GraphML, SVG, Obsidian vault ou Neo4j Cypher. |
| Génère automatiquement un wiki Markdown basé sur la structure de la communauté. |
| Effectue une analyse d'impact avec évaluation des risques. |
Dans les outils prenant en charge les Slash Commands, on peut également utiliser directement /code-review-graph:build-graph, /code-review-graph:review-delta et /code-review-graph:review-pr pour invoquer les flux de travail correspondants.
Quels sont les résultats ?
Les benchmarks officiels, basés sur 6 dépôts open source réels et 13 commits, montrent que le mode graph réduit en moyenne la consommation de tokens à environ un huitième de celle de la lecture naïve complète, soit une réduction globale d'un facteur 8,2. D'après les données publiques, les gains varient d'un dépôt à l'autre, mais la plupart des projets de taille moyenne à grande présentent une baisse significative.
Projet | Réduction des tokens (x) |
|---|---|
Gin | 16.4× |
Flask | 9.1× |
FastAPI | 8.1× |
Next.js | 8.0× |
httpx | 6.9× |
Moyenne | 8.2× |
Un autre indicateur important est la précision de l'analyse d'impact. Les résultats officiels indiquent un rappel de 100 %, un F1 moyen de 0,54 et une précision moyenne de 0,38. Cela montre que sa stratégie est plutôt conservatrice : il préfère suggérer plus de fichiers « potentiellement affectés » que de manquer une dépendance réellement impactée.
Métrique | Valeur | Signification |
|---|---|---|
Recall | 100% | Ne manque pas les fichiers réellement affectés |
F1 | 0.54 | Mesure combinée du rappel et de la précision |
Precision | 0.38 | Tendance conservatrice, peut inclure davantage de fichiers candidats |
Cependant, cette approche n'est pas avantageuse dans tous les scénarios. La documentation officielle mentionne clairement que dans les projets de petite taille avec des modifications très localisées, le surcoût contextuel des métadonnées du graphe peut être supérieur au coût de la lecture directe des fichiers ; par exemple, dans le test de modification d'un seul fichier d'express, la réduction n'est que de 0,7x. Par conséquent, les scénarios les mieux adaptés restent les projets de taille moyenne à grande, les modifications multi-fichiers, les dépendances complexes et les flux de travail de révision IA fréquents.
À quelles équipes cela convient-il ?
Si une équipe a déjà intégré Claude Code, Codex, Cursor ou des outils similaires dans son flux de développement quotidien, et que le projet est de grande taille, avec des relations de modules complexes et des revues de PR fréquentes, alors la valeur de code-review-graph sera assez directe. Il ne remplace pas fondamentalement la révision de code, mais aide d'abord l'IA à déterminer « ce qu'il faut lire », de sorte que les révisions ultérieures, le débogage, l'analyse architecturale et l'onboarding reposent sur un contexte plus précis.
Pour les projets individuels, les très petits dépôts ou les modifications simples ponctuelles, il n'apporte pas toujours des bénéfices évidents. Mais pour les équipes qui souhaitent réduire systématiquement les coûts de codage IA, diminuer le bruit contextuel et améliorer le taux de pertinence des révisions de code, il a déjà montré des résultats assez pratiques.
Suivre sur Google
Ajouter HeyBinyang comme source préférée sur Google
Si vous souhaitez retrouver plus facilement mes mises à jour via Google, vous pouvez marquer ce site comme source préférée.
Partager
Partager
Partager cet article.