code-review-graph: revisiones de código con IA más precisas y con menos tokens
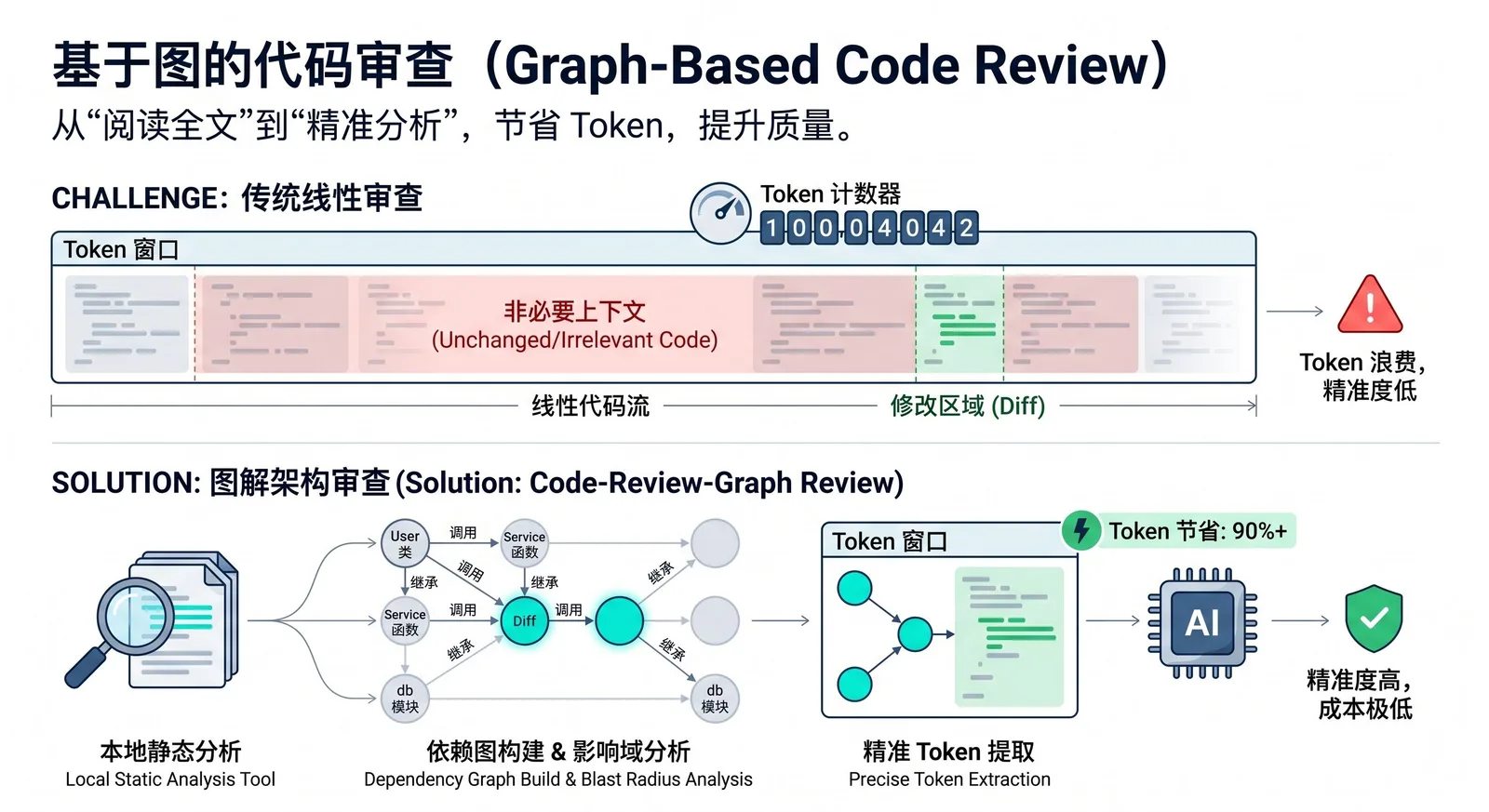
code-review-graph es una herramienta de código abierto orientada a asistentes de codificación de IA. Primero construye un «grafo de conocimiento» estructurado localmente para el repositorio de código, y luego entrega el contexto realmente relevante a la IA, evitando así escanear todo el repositorio por completo en cada tarea. Se basa en Tree-sitter para analizar el AST, organiza funciones, clases, importaciones, relaciones de llamadas y relaciones de prueba en una estructura de grafo, y luego lo proporciona a herramientas como Claude Code, Codex, Cursor, etc. a través de MCP.
¿Qué problema resuelve?
Actualmente, muchas herramientas de codificación con IA, al realizar revisiones de código, localizar el alcance de impacto o entender cambios, leen repetidamente todo el repositorio, lo que genera un desperdicio notable de Tokens y un aumento de costos. En un repositorio con cientos de archivos, incluso si solo se modifica una función, la IA puede necesitar volver a escanear muchos archivos irrelevantes, lo que ralentiza el proceso, aumenta el ruido de contexto y eleva los costos.
La idea de code-review-graph es modelar previamente las «relaciones de dependencia del código», de modo que al revisar, la IA solo lea los archivos realmente afectados por los cambios, en lugar de hacer un escaneo completo basado en suposiciones. La documentación oficial llama a esta capacidad «blast-radius analysis», es decir, «análisis de radio de explosión»: cuando un archivo cambia, la herramienta rastrea a lo largo de las cadenas de llamadas, herencia, dependencias y pruebas para encontrar todo el código que podría verse afectado.
¿Cómo funciona?
Primero, la herramienta analiza el repositorio con Tree-sitter para convertirlo en AST y extrae información estructural como funciones, clases, importaciones, puntos de llamada, relaciones de herencia y cobertura de pruebas. Luego almacena esta información en una base de datos de grafos SQLite local. En la fase de revisión, la IA no lee todo el proyecto directamente, sino que primero consulta el grafo para obtener un conjunto mínimo de contexto, leyendo solo los archivos y nodos directamente relevantes al problema actual.
También admite actualizaciones incrementales. La documentación oficial indica que las actualizaciones posteriores solo reanalizan los archivos que han cambiado y actualizan los nodos relacionados mediante hashes y seguimiento de dependencias; en un proyecto de aproximadamente 2.900 archivos, la reindexación se puede realizar en menos de 2 segundos. Este enfoque es especialmente valioso para repositorios grandes como monorepos, ya que puede reducir de decenas de miles de archivos a solo una docena de archivos realmente necesarios para leer.
Plataformas y herramientas compatibles
code-review-graph se integra con múltiples plataformas de codificación de IA a través de MCP. Los compatibles listados en la guía de inicio rápido y la documentación de la plataforma incluyen Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro, OpenCode, Antigravity, Qwen y Qoder. Esto significa que no se limita a un editor de IA específico, sino que intenta conectar la capacidad de «contexto de grafo» a diferentes agentes de codificación o IDE de IA.
Tipo | Plataformas/herramientas compatibles |
|---|---|
Herramientas oficiales de codificación de IA | Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro |
Otras plataformas listadas | OpenCode, Antigravity, Qwen, Qoder |
Forma de integración | Se integra a través de MCP, invocando la capacidad de grafo en las plataformas compatibles |
Si solo se desea instalar para una plataforma específica, también se puede especificar explícitamente el nombre de la plataforma, por ejemplo code-review-graph install --platform codex, code-review-graph install --platform cursor, code-review-graph install --platform claude-code o code-review-graph install --platform kiro.
Cómo usar
El flujo básico es simple: primero instalar, luego escribir la configuración MCP en la herramienta de IA y finalmente construir el grafo en el proyecto específico.
pip install code-review-graph
code-review-graph install
cd /path/to/your/project
code-review-graph build
Aquí hay un punto muy importante y fácil de malinterpretar: code-review-graph install no es un «comando de inicialización de proyecto» que se ejecuta en la raíz del proyecto; es esencialmente un comando de configuración global. La documentación oficial deja claro que este comando detecta automáticamente las herramientas de codificación de IA instaladas en tu máquina, escribe la configuración MCP correspondiente e inyecta las instrucciones relacionadas con el grafo en las reglas de esas plataformas; después de ejecutarlo, es necesario reiniciar el editor o herramienta correspondiente.
Por otro lado, code-review-graph build es el comando que debe ejecutarse en la raíz del proyecto. La documentación oficial indica «Luego abre tu proyecto» y pide al asistente de IA que construya el grafo de revisión de código para «este proyecto»; además, el archivo de ignorados .code-review-graphignore debe colocarse en la raíz del repositorio, y los datos locales del grafo se almacenan en el directorio .code-review-graph/ del proyecto. En otras palabras, install se encarga de conectar la capacidad a tu herramienta de IA, mientras que build construye el grafo para el repositorio actual.
Para evitar confusiones en los lectores, podemos contrastar claramente las responsabilidades de estos dos comandos:
Comando | ¿Se ejecuta en la raíz del proyecto? | Función |
|---|---|---|
| No, no se requiere en la raíz del proyecto | Detecta herramientas de IA instaladas y escribe la configuración MCP correspondiente |
| Sí, se requiere ejecutar en la raíz del proyecto objetivo | Construye el grafo local para el repositorio actual y genera el directorio |
Si el editor no admite hooks, o si se desea que el grafo se mantenga siempre actualizado en segundo plano, también se puede usar el modo daemon. La documentación oficial proporciona comandos como crg-daemon add, crg-daemon start, crg-daemon status para registrar múltiples repositorios y monitorear automáticamente los cambios de archivos.
Comandos comunes
Además de la instalación y construcción del grafo, la documentación oficial también describe las capacidades completas de la CLI.
Comando | Descripción |
|---|---|
| Detecta automáticamente y configura todas las plataformas compatibles. |
| Configura solo la plataforma especificada. |
| Analiza completamente el repositorio actual y crea el grafo. |
| Actualiza incrementalmente solo los archivos modificados. |
| Monitorea continuamente los cambios de archivos y actualiza automáticamente el grafo. |
| Genera un grafo interactivo en HTML; también puede exportar a GraphML, SVG, Obsidian vault o Neo4j Cypher. |
| Genera automáticamente un wiki en Markdown basado en la estructura de la comunidad. |
| Realiza un análisis de impacto de cambios con puntuación de riesgo. |
En herramientas que admiten Slash Commands, también se puede usar directamente /code-review-graph:build-graph, /code-review-graph:review-delta y /code-review-graph:review-pr para invocar los flujos de trabajo correspondientes.
Resultados
Los benchmarks oficiales se basan en 6 repositorios de código abierto reales y 13 commits. Los resultados muestran que el modo grafo, en comparación con la lectura completa ingenua, reduce el consumo de Tokens a aproximadamente un octavo del original, una reducción media de 8.2 veces. Según los datos públicos, los beneficios no son exactamente iguales en todos los repositorios, pero la mayoría de los proyectos de tamaño mediano a grande muestran una disminución significativa.
Proyecto | Reducción de Tokens (veces) |
|---|---|
Gin | 16.4× |
Flask | 9.1× |
FastAPI | 8.1× |
Next.js | 8.0× |
httpx | 6.9× |
Promedio | 8.2× |
Otro indicador importante es la precisión del análisis de impacto. Los resultados oficiales muestran una tasa de recuperación del 100%, un F1 promedio de 0.54 y una precisión promedio de 0.38. Esto indica que la estrategia tiende a ser conservadora: prefiere sugerir archivos «posiblemente afectados» en exceso que pasar por alto dependencias que realmente puedan verse afectadas por el cambio.
Métrica | Valor | Significado |
|---|---|---|
Recall | 100% | No omite los archivos realmente afectados |
F1 | 0.54 | Medida combinada de recuperación y precisión |
Precision | 0.38 | Tiende a ser conservador, puede incluir archivos candidatos de más |
Sin embargo, este enfoque no es ventajoso en todos los escenarios. La documentación oficial menciona explícitamente que en proyectos pequeños con cambios muy localizados, la sobrecarga de contexto de los metadatos del grafo puede ser mayor que el costo de leer directamente los archivos. Por ejemplo, en la prueba de cambio de un solo archivo en express, la reducción fue solo de 0,7×. Por lo tanto, los escenarios más adecuados siguen siendo proyectos de tamaño mediano a grande, cambios en múltiples archivos, dependencias complejas y flujos de trabajo de revisión frecuentes con IA.
¿Para qué equipos es adecuado?
Si el equipo ya ha integrado Claude Code, Codex, Cursor o herramientas similares en su flujo de trabajo diario, y el proyecto es grande, con módulos complejos y revisiones de PR frecuentes, entonces el valor de code-review-graph será bastante directo. No sustituye la revisión de código, sino que primero ayuda a la IA a hacer bien la tarea de «qué leer», permitiendo que las revisiones, depuración, análisis de arquitectura e incorporación se basen en un contexto más preciso.
Para proyectos individuales, repositorios muy pequeños o cambios simples ocasionales, puede que no siempre traiga beneficios evidentes. Pero para equipos que buscan reducir sistemáticamente los costos de codificación con IA, disminuir el ruido de contexto y mejorar la precisión de las revisiones de código, ya ha demostrado ser bastante práctico.
Seguir en Google
Añadir HeyBinyang como fuente preferida en Google
Si quieres seguir encontrando mis actualizaciones en Google, puedes marcar este sitio como fuente preferida.
Compartir
Compartir
Comparte este artículo.