MCP-Einstiegsleitfaden für Frontend-Entwickler
Viele Frontend-Ingenieure sind beim ersten Kontakt mit MCP etwas verwirrt: Der Name klingt wie ein Protokoll, der Inhalt wie ein Agent, und in Diskussionen tauchen ständig Tool, Prompt, Resource, Skill auf. Eigentlich muss man nicht alle Begriffe auf einmal verstehen, man muss sich nur einen Satz merken: MCP ist ein standardisierter Weg, um KI mit Werkzeugen zu verbinden, Daten zu holen und wirklich etwas zu tun.
Wenn man das bisherige große Modell mit einem Kollegen vergleicht, der nur reden kann, dann kann es nach der Integration von MCP die Fähigkeit erlangen, Systeme abzufragen, Schnittstellen aufzurufen und Dateien zu lesen. Es beantwortet nicht nur Fragen, sondern kann auch innerhalb der Autorisierungsgrenzen Aktionen für dich ausführen. Das ist einer der Hauptgründe, warum MCP von immer mehr KI-Entwicklungstools übernommen wird.
Was ist MCP
MCP steht für Model Context Protocol und ist ein offenes Protokoll, das LLM-Anwendungen mit externen Datenquellen, Tools und Systemfähigkeiten verbindet.
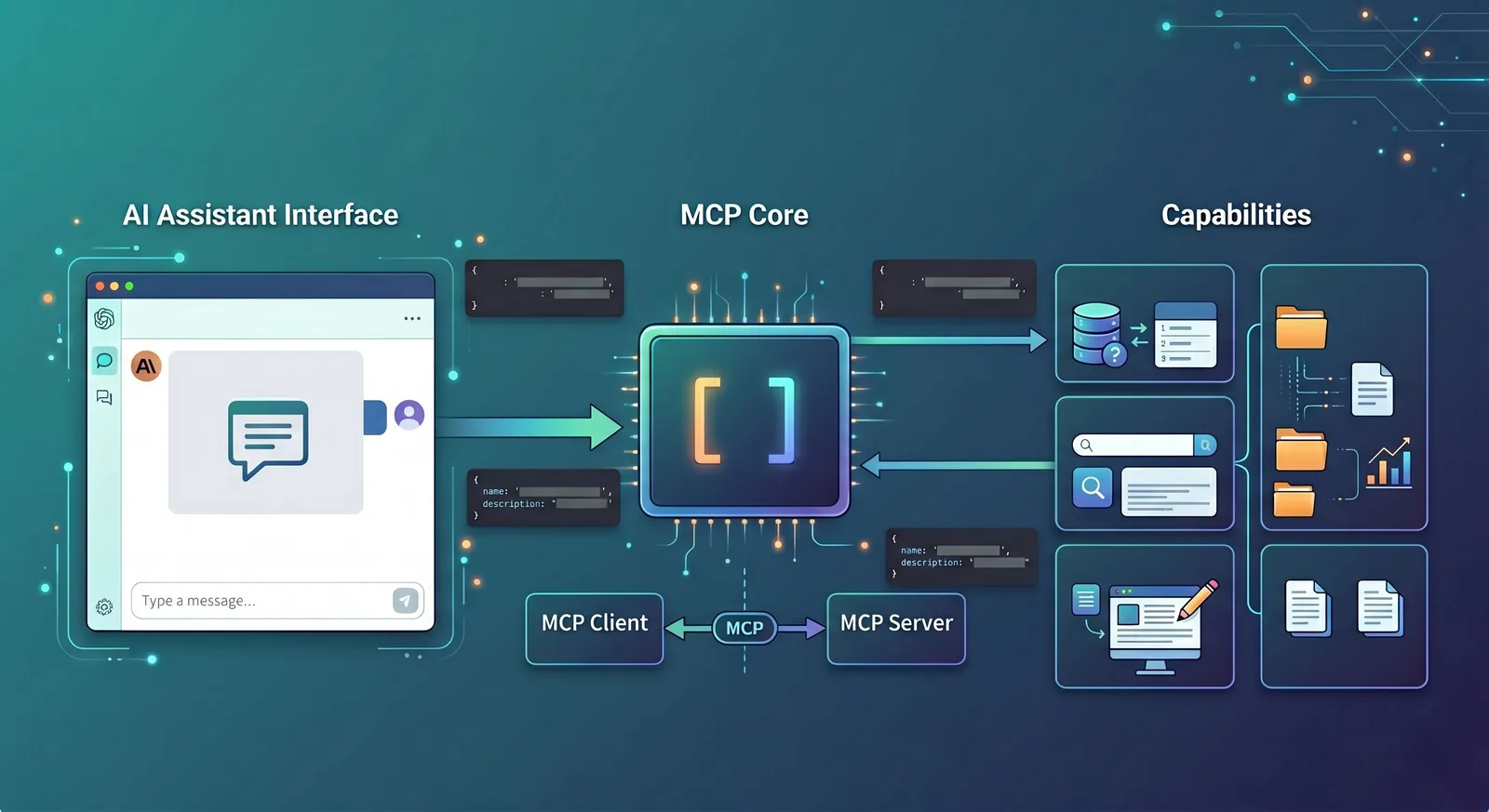
Wenn man es aus der Frontend-Perspektive versteht: HTTP regelt die Kommunikation zwischen Browser und Server, während MCP die Kommunikation zwischen KI-Anwendungen und Tools, Ressourcen und Kontext regelt.
Die offizielle Architekturdokumentation unterteilt die Kommunikationsrollen in Host, Client und Server: Der Host ist die LLM-Anwendung, die die Verbindung initiiert, der Client ist der Connector im Host, und der Server ist der Anbieter von Tool- und Kontextfähigkeiten.
Dieses Design ist dem aus dem Frontend bekannten 'Host-Anwendung + SDK + Server' sehr ähnlich. Du kannst es dir so vorstellen: Der Host ist für die Oberfläche und das Modell verantwortlich, der Client für die Kommunikation gemäß Protokoll und der Server für die tatsächliche Bereitstellung von Fähigkeiten.
Sehen wir uns ein anschauliches Beispiel an
Angenommen, du hast ein Backend-System erstellt und in der unteren rechten Ecke einen KI-Assistenten platziert. Ein Benutzer fragt: „Wie viele neue Bestellungen gibt es heute?“
Ohne MCP würde dieser Assistent normalerweise nur auf der Chatebene bleiben: Entweder errät er ein Ergebnis basierend auf Trainingsdaten, oder du musst selbst ein zusätzliches Tool-Aufrufformat schreiben und die Datenbankabfrageschnittstelle und Berechtigungslogik hart einbinden.
Mit MCP wird der Ablauf viel klarer. Der KI-Assistent fragt zuerst einen MCP Server: „Welche Tools hast du?“ Der Server gibt eine Liste von Tools zurück, zum Beispiel get_today_orders, get_order_detail, export_report, jedes Tool mit einer Beschreibung und einem Parameterschema.
Dann sieht das Modell die Benutzerfrage und wählt get_today_orders aufzurufen. Der Server fragt die Datenbank ab, gibt das Ergebnis an die KI zurück, und die KI antwortet in natürlicher Sprache: „Heute gibt es 128 neue Bestellungen.“ Das ist die typischste Verwendung von MCP: Zuerst das Tool entdecken, dann das Tool aufrufen und dann das Ergebnis in für den Benutzer verständliche Worte fassen.
Wer sind Host, Client und Server eigentlich?
Diese drei Begriffe treten oft zusammen auf, sind aber überhaupt nicht schwer zu verstehen. Man kann sie mit einer „Lieferplattform“ vergleichen: Der Host ist wie die Liefer-App, der Client wie das Dispositionssystem in der App und der Server wie der Restaurantbetreiber, der das Essen tatsächlich zubereitet.
Übertragen auf MCP:
Der Host ist die KI-Anwendung, die du direkt siehst, z. B. Claude Desktop, Claude Code, ein IDE-Plugin oder deine eigene Web-KI-Seite.
Der Client ist die Schicht im Host, die für die Kommunikation mit der Außenwelt gemäß dem MCP-Protokoll zuständig ist.
Der Server ist die Seite, die tatsächlich Fähigkeiten bereitstellt, z. B. Logging-Dienste, Dateisystem-Adapter, Datenbankabfragedienste, GitHub-Tool-Dienste.
Ein Entwicklungsszenario: Angenommen, du verwendest einen KI-Programmierassistenten in VS Code und bittest ihn: „Zeig mir, welche Schnittstelle im aktuellen Projekt die meisten Timeouts hat.“ Der KI-Assistent in VS Code ist der Host, der Client im Assistenten ist für die Protokollkommunikation zuständig, und die Anbieter, die auf Logs, Code-Repositorys und Überwachungsplattformen zugreifen können, sind die MCP Server.
Tool ist das, was du zuerst verstehen solltest
Das Wichtigste in MCP ist nicht Prompt, nicht Resource, sondern Tool. Denn die meisten Erfahrungen, bei denen KI wirklich anfängt zu arbeiten, beginnen mit einem Tool.
Du kannst dir ein Tool als eine „Schnittstelle für KI“ vorstellen. Es enthält normalerweise drei Dinge: den Toolnamen, eine Beschreibung und ein Parameterschema, also die Strukturdefinition der Parameter.
Ein Wetter-Tool könnte zum Beispiel so aussehen:
name:
get_weatherdescription: Aktuelles Wetter einer Stadt abfragen
input schema:
location, Typ string, erforderlich.
Wenn der Client es aufruft, sendet er über eine Anfrage wie tools/call den Toolnamen und die Parameter. Die offizielle Tool-Spezifikation und Beispiele folgen diesem Muster.
Ein weiteres Beispiel, das näher am Frontend liegt: Du hast ein Content-Backend erstellt und kannst dem KI-Assistenten drei Tools bereitstellen:
search_articles: Artikel nach Schlagwort suchen.get_article_detail: Details eines Artikels abrufen.publish_article: Artikel veröffentlichen.
So hat die KI die Möglichkeit, wenn der Benutzer sagt: „Finde die Entwürfe mit MCP im Titel und veröffentliche den neuesten“, zuerst die Liste zu durchsuchen, dann die Details abzurufen und dann die Veröffentlichungsschnittstelle aufzurufen. Du wirst feststellen, dass dies im Grunde eine Reihe von Backend-APIs sind, die dem Modell zur kombinierten Nutzung bereitgestellt werden.
Warum das Schema wichtig ist
Viele Leute denken beim ersten Anblick von MCP: „Toolname + Beschreibung reicht doch, warum muss man noch ein Schema schreiben?“ Der Grund ist einfach: Das Modell ruft Tools nicht durch Raten auf; es braucht einen klaren Parametervertrag.
Zum Beispiel, wenn du ein Tool create_user schreibst, weiß das Modell ohne Schema möglicherweise nicht, ob email erforderlich ist oder ob age eine Zahl oder ein String sein soll. Mit einem Schema wissen sowohl das Modell als auch der Client genau, wie die Parameter zu konstruieren sind; das Frontend kann basierend auf diesen Strukturen direkt Debugging-Formulare oder Typdefinitionen generieren, was der Erfahrung beim Abstimmen von Schnittstellen mit Swagger-Dokumentation sehr nahe kommt.
Deshalb ist MCP auch für Frontend-Ingenieure sehr freundlich. Es ist keine Methode, die sich vollständig auf Prompt-Raten verlässt, sondern versucht, die Tool-Fähigkeiten so strukturiert, eindeutig und überprüfbar wie möglich zu machen.
Wie genau ein vollständiger Aufruf abläuft
Wieder ein einfaches Szenario: Der Benutzer gibt im KI-Assistenten ein: „Finde heraus, wie viele neue registrierte Benutzer es heute gibt.“
Schritt 1: Der Host weiß zunächst, mit welchen MCP Servern er verbunden ist, z. B. einem Analytics-Server. Dieser Server stellt das Tool get_signup_count bereit.
Schritt 2: Der Client erhält über tools/list die Tooldefinition und erfährt, dass dieses Tool einen Parameter date vom Typ String benötigt.
Schritt 3: Das Modell entscheidet, dass dieser Aufruf get_signup_count erfordert, also sendet der Client eine tools/call-Anfrage mit Parameter { "date": "2026-05-03" }.
Schritt 4: Der Server fragt die Datenbank oder den Analysedienst ab und gibt ein Ergebnis zurück, z. B. 356. Dann formatiert der Host dieses Ergebnis in eine benutzerfreundliche Antwort: „Heute haben sich 356 neue Benutzer registriert.“
Der entscheidende Punkt in diesem Prozess ist: Das Modell greift nicht direkt auf die Datenbank zu, sondern führt die Aktion indirekt über ein klar definiertes Tool aus. So werden Berechtigungen, Sicherheit, Überwachung und Fehlerbehandlung viel einfacher.
Resource und Prompt: Man muss zunächst nur wissen, wofür sie da sind
Neben Tool werden in MCP auch häufig Resource und Prompt erwähnt. Sie sind nützlich, aber in der Anfangsphase muss man nicht tief in sie eintauchen.
Resource ist eher wie „Material für das Modell“, nicht unbedingt ausführbare Aktionen. Zum Beispiel Fehlerprotokolle der letzten Stunde, der Inhalt der aktuell geöffneten Datei, die README eines Projekts oder Datenbanktabellenstrukturen können als Resource für das Modell bereitgestellt werden.
Wenn der Benutzer fragt: „Warum hat diese Schnittstelle ständig Timeouts?“, muss die KI möglicherweise nicht viele Tools sofort aufrufen, sondern zuerst eine Log-Resource und eine Code-Resource lesen und dann das Problem analysieren. Offizielle Beispiele zu Prompts und Resources zeigen diese Verwendung, bei der Protokolle und Codedateien zusammen dem Modell bereitgestellt werden.
Prompt ist eher wie eine wiederverwendbare Aufgaben-Vorlage. Zum Beispiel ein git-commit Prompt, der Codeänderungen als Eingabe nimmt und eine einheitlich formatierte Commit-Nachricht ausgibt; oder ein explain-code Prompt, der speziell zum Erklären von Code dient.
Wenn du dir nur den einfachsten Unterschied merken willst: Tool ist ein „Knopf, der etwas tut“, Resource ist „Material für das Modell“ und Prompt ist eine „häufig verwendete Arbeitsvorlage“.
Warum das Frontend deutlich profitiert
Der größte Vorteil für das Frontend ist nicht, dass es „auch Protokolle schreiben kann“, sondern dass die Interaktionsweise verändert wird.
Früher hatte der KI-Assistent auf der Seite normalerweise nur ein Eingabefeld und konnte nur sehr begrenzte Dinge tun. Wenn jetzt im Hintergrund MCP integriert ist, kann das Frontend viele Dinge explizit anzeigen, z. B. welche Tools die KI hat, welches Tool gerade aufgerufen werden soll, warum bestimmte Berechtigungen angefordert werden, wie das Aufrufergebnis aussieht und bei welchem Schritt ein Fehler aufgetreten ist.
Das macht KI-Produkte eher zu einer „beobachtbaren, steuerbaren Arbeitsplattform“ als zu einer Black-Box-Chatbox. Besonders in Szenarien wie Backend-Systemen, IDEs und internen Tools möchten Benutzer normalerweise sehen, was die KI tatsächlich getan hat, anstatt nur eine mysteriöse Antwort zu erhalten.
Ein weiteres Beispiel aus dem Frontend-Workflow: Du erstellst eine Log-Analyse-Seite. Nachdem der Benutzer auf einen Fehlerlog klickt, erhält der KI-Assistent auf der rechten Seite automatisch diesen Kontext: aktueller Dienstname, Fehlerzeitraum, ausgewähltes Log-Fragment, aktueller Repository-Branch-Name.
Dann sagt der Benutzer nur: „Analysiere die Ursache.“ Die KI kann dann zuerst die Log-Resource lesen, dann Tools wie search_recent_deploys, get_error_rate aufrufen und schließlich eine zuverlässigere Analyse zurückgeben. Der Schlüssel zu dieser Erfahrung liegt nicht darin, dass das Modell schlauer ist, sondern dass das Frontend den UI-Status in einen für das Modell nutzbaren Kontext umwandelt.
Wo steht MCP jetzt?
Seit 2025/2026 wird in der Community am meisten über Skill, Workflow und Agent Orchestrierung diskutiert, und die Aufmerksamkeit für MCP scheint tatsächlich geringer zu sein als zu Beginn. Aber aus technischer Sicht, so beliebt Skill auch ist, dahinter steckt oft immer noch MCP, das die Arbeit erledigt.
Ein konkretes Beispiel macht es deutlich:
Skill ist wie ein Skript und ein Ablauf für die „Bearbeitung von Rückerstattungen im Kundenservice“: Zuerst die Bestellung bestätigen, dann den Zahlungsstatus prüfen, dann die Risikokontrolle überprüfen und schließlich das Ergebnis mitteilen.
MCP ist wie die „einheitliche Schnittstellenschicht hinter dem Kundenservice-System“, die dir hilft, Bestell-, Zahlungs- und Risikodienste anzubinden, sodass jeder Schritt „mal nachschauen“ ein entsprechendes Tool zum Aufrufen hat.
Im Entwicklungsszenario ist es ähnlich:
Skill kann definieren, „wie eine Code-Review durchgeführt wird“: zuerst das Diff ansehen, dann die Tests, dann die Fehlerlogs und schließlich die Review-Anmerkungen generieren.
Die tatsächlichen Aktionen wie Diff abrufen, CI prüfen und Logs lesen werden normalerweise über Tools ausgeführt, die von MCP bereitgestellt werden; Skill ist dafür verantwortlich, „in welcher Reihenfolge welche Tools verwendet werden“, während MCP dafür verantwortlich ist, „wie diese Tools verbunden, aufgerufen und Ergebnisse abgerufen werden“.
Die aktuelle Situation ist also eher: Nach außen hin wird mehr über die Intelligenz von Skill und die Automatisierung der Abläufe gesprochen; aber auf der Basisebene, im Code, bleibt MCP die stabile „Steckdosenleiste“, die das Modell mit verschiedenen Geschäftssystemen, Sicherheits-Gateways, Datenbanken und Logging-Plattformen verbindet.
Sein Name ist vielleicht nicht so angesagt wie Skill, aber solange du ein Produkt entwickelst, das KI wirklich Systeme bedienen und echte Daten abfragen lässt, muss die Protokollebene von jemandem getragen werden, und MCP spielt genau diese ruhige, aber entscheidende Rolle in vielen Projekten.
Der Unterschied zwischen MCP und Skill
Wenn man es in einem Satz unterscheidet: MCP löst „Wie werden Tools angeschlossen?“, Skill löst „Wie wird die Aufgabe erledigt?“.
Wieder das Beispiel „Code-Review-Assistent“.
Wenn du dich jetzt fragst: Wie kann die KI auf Git Diffs zugreifen? Wie kann sie CI-Ergebnisse abrufen? Wie kann sie Lint-Berichte lesen? Dann hast du ein MCP-Problem, denn das alles gehört zu „Fähigkeiten anbinden“.
Aber wenn du dich fragst: Was soll bei der Code-Review zuerst angesehen werden? Welche Risiken sollen priorisiert werden? In welchem Format sollen die Ergebnisse ausgegeben werden? Wann sollten zusätzliche Tests vorgeschlagen werden? Dann ist das eher ein Skill-Problem, weil es definiert, „wie diese Sache gemacht werden soll“.
In der Realität treten beide normalerweise zusammen auf. MCP ist für die Verbindung von Git, CI und Logging-Plattformen zuständig, während Skill den „Code-Review-Prozess“ festlegt. Aber für das grundlegende Verständnis reicht es aus, diese Grenze zunächst zu kennen.
Warum es sich zu lernen lohnt
MCP ist lernenswert, nicht weil es ein neuer Begriff ist, sondern weil es die Schicht standardisiert, die in der KI-Produktentwicklung am chaotischsten ist: Tool-Erkennung, Parameterbeschreibung, Kontextübertragung und Ausführungsaufrufe.
Wenn diese Schicht standardisiert ist, müssen Frontend-Ingenieure nicht jedes Mal, wenn sie ein neues KI-Produkt erstellen, ein neues Protokoll für „wie das Modell Backend-Fähigkeiten anbindet“ erfinden.
Wichtiger noch, diese Standardisierung wird die Verantwortungsgrenzen des Frontends interessanter machen. Die Seite wird nicht mehr nur ein Container für Ein- und Ausgabe sein, sondern nach und nach zu einer Konsole für das KI-Verhalten werden: Tools anzeigen, Status erklären, Pläne präsentieren, Autorisierungen anfordern, Ergebnisse zurückmelden.
Das ermöglicht Frontend-Ingenieuren, in KI-Produkten nicht nur „ein SDK einzubinden“, sondern wirklich an der Definition der Mensch-Maschine-Kollaboration mitzuwirken.
Fazit
Wenn man es in einem Satz zusammenfasst: Der Wert von MCP liegt darin, dass KI-Anwendungen zum ersten Mal eine relativ einheitliche, wiederverwendbare und ingenieurmäßige „externe Fähigkeitsanbindungsschicht“ haben.
Für Frontend-Ingenieure ist es nicht nötig, zuerst KI-Experten zu werden, um es zu verstehen. Man muss es nur als eine neue Protokollebene betrachten, eine standardisierte Verbindungsweise, die es der Oberfläche, dem Modell und den Geschäftssystemen ermöglicht, zusammenzuarbeiten.
Auf Google folgen
HeyBinyang als bevorzugte Quelle bei Google hinzufügen
Wenn du meine Updates über Google leichter finden möchtest, kannst du diese Website als bevorzugte Quelle markieren.
Teilen
Teilen
Diesen Artikel teilen.