code-review-graph: KI-Code-Reviews präziser und token-sparender
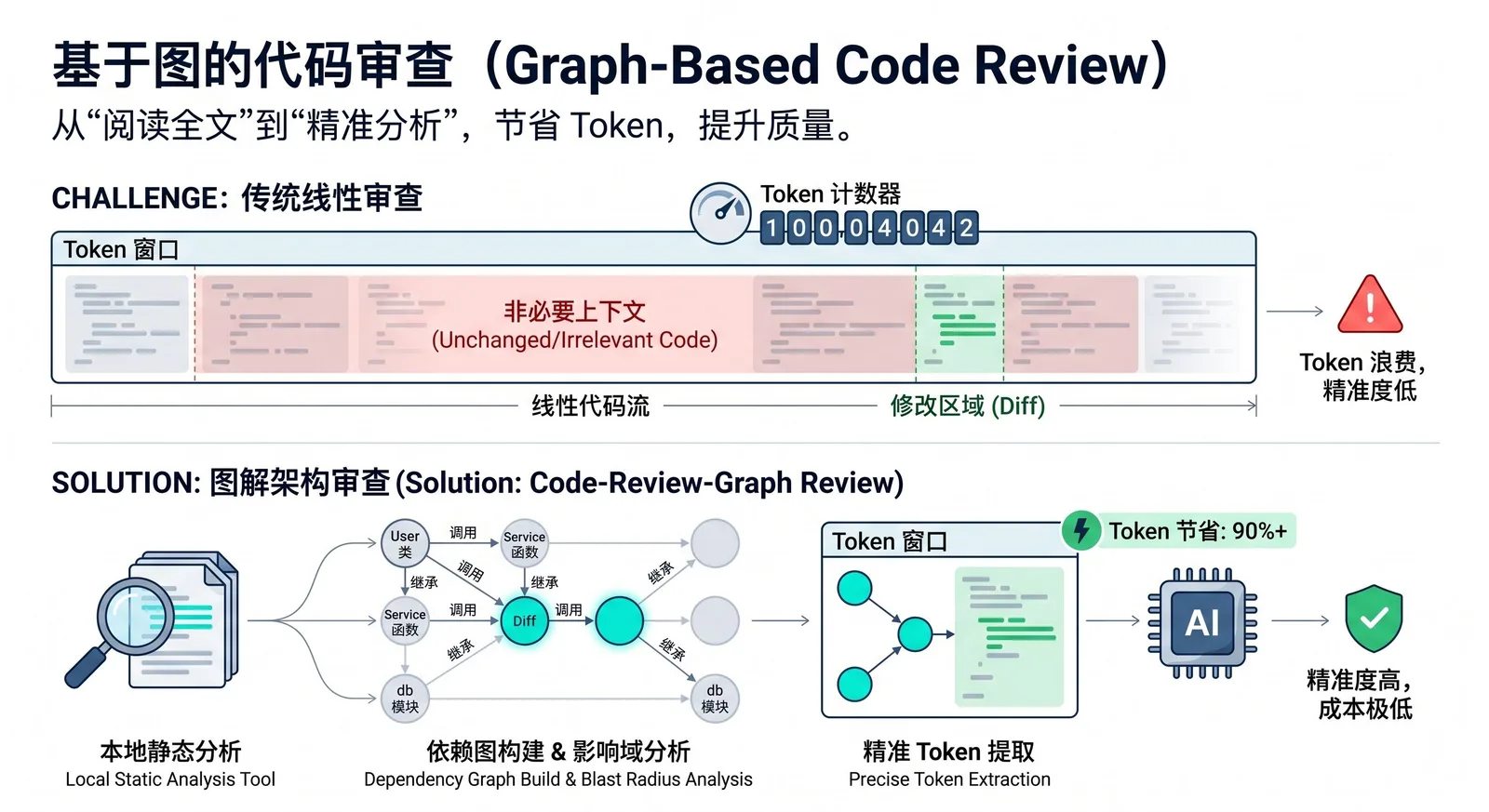
code-review-graph ist ein Open-Source-Tool für KI-Code-Assistenten. Es erstellt zunächst lokal eine strukturierte „Wissensgraph“ des Codebestands und übergibt dann nur den wirklich relevanten Kontext an die KI, um zu vermeiden, dass bei jeder Aufgabe das gesamte Repository vollständig gescannt wird. Es basiert auf Tree-sitter zur Analyse des AST, organisiert Funktionen, Klassen, Importe, Aufrufbeziehungen und Testabhängigkeiten in einer Graphstruktur und stellt diese über MCP für Tools wie Claude Code, Codex, Cursor usw. zur Verfügung.
Welches Problem es löst
Viele aktuelle KI-Code-Tools lesen bei Code-Reviews, der Bestimmung von Auswirkungsbereichen oder dem Verständnis von Änderungen wiederholt das gesamte Code-Repository aus, was zu erheblichen Token-Verschwendungen und steigenden Kosten führt. In einem Repository mit Hunderten von Dateien muss die KI, selbst wenn nur eine Funktion geändert wird, möglicherweise viele irrelevante Dateien erneut scannen, was zu Langsamkeit, mehr Kontextrauschen und höheren Kosten führt.
Die Idee von code-review-graph besteht darin, die „Code-Abhängigkeitsbeziehungen“ im Voraus zu modellieren, damit die KI beim Review nur die Dateien liest, die von der Änderung tatsächlich betroffen sind, anstatt auf eine vollständige Suche zu setzen. Die offizielle Dokumentation bezeichnet diese Fähigkeit als „blast-radius analysis“, also „Explosionsradius-Analyse“: Wenn eine Datei geändert wird, verfolgt das Tool entlang der Aufruf-, Vererbungs-, Abhängigkeits- und Testketten nach außen und findet alle potenziell betroffenen Codeteile.
Wie es funktioniert
Das Tool analysiert das Repository zunächst mit Tree-sitter in einen AST und extrahiert Strukturinformationen wie Funktionen, Klassen, Importe, Aufrufstellen, Vererbungsbeziehungen und Testabdeckungen. Diese Informationen werden in einer lokalen SQLite-Graphdatenbank gespeichert. In der Review-Phase liest die KI nicht mehr das gesamte Projekt direkt, sondern fragt zuerst den Graphen ab, um einen minimalen Kontextsatz zu erhalten, der nur die für das aktuelle Problem direkt relevanten Dateien und Knoten liest.
Es unterstützt auch inkrementelle Aktualisierungen. Laut offizieller Angaben werden bei späteren Aktualisierungen nur die geänderten Dateien neu analysiert, und die relevanten Knoten werden über Hashes und Abhängigkeitsverfolgung aktualisiert. In einem Projekt mit etwa 2.900 Dateien kann die Neuindizierung innerhalb von 2 Sekunden abgeschlossen werden. Für große Repositorys wie Monorepos ist dieser Ansatz besonders wertvoll, da er von zehntausenden Dateien auf nur ein Dutzend tatsächlich zu lesender Dateien reduziert.
Unterstützte Plattformen und Tools
code-review-graph wird über MCP in verschiedene KI-Code-Plattformen integriert. Die offizielle Schnellstartanleitung und die Plattformbeschreibung listen folgende unterstützte Tools auf: Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro, OpenCode, Antigravity, Qwen und Qoder. Das bedeutet, dass es nicht auf einen bestimmten KI-Editor beschränkt ist, sondern versucht, die „Graph-Kontext“-Fähigkeit auf verschiedene Coding-Agenten oder KI-IDEs zu übertragen.
Typ | Unterstützte Plattformen/Tools |
|---|---|
Offizielle KI-Code-Tools | Claude Code, Codex, Cursor, Windsurf, Zed, Continue, Kiro |
Weitere gelistete Plattformen | OpenCode, Antigravity, Qwen, Qoder |
Integrationsmethode | Über MCP angebunden, ruft Graphenfähigkeiten auf unterstützten Plattformen auf |
Wenn Sie das Tool nur für eine bestimmte Plattform installieren möchten, können Sie den Plattformnamen explizit angeben, z. B. code-review-graph install --platform codex, code-review-graph install --platform cursor, code-review-graph install --platform claude-code oder code-review-graph install --platform kiro.
Wie man es verwendet
Der grundlegende Ablauf ist einfach: Zuerst installieren, dann die MCP-Konfiguration in das KI-Tool schreiben und schließlich im konkreten Projekt den Graphen erstellen.
pip install code-review-graph
code-review-graph install
cd /path/to/your/project
code-review-graph build
Hier ist ein sehr wichtiger und leicht misszuverstehender Punkt: code-review-graph install ist nicht ein „Projektinitialisierungsbefehl“, der im Projektstammverzeichnis ausgeführt wird; es handelt sich im Wesentlichen um einen globalen Konfigurationsbefehl. Die offizielle Dokumentation stellt klar, dass dieser Befehl automatisch die auf Ihrem Rechner installierten KI-Code-Tools erkennt, die entsprechende MCP-Konfiguration schreibt und die graphbezogenen Anweisungen in die Regelkonfiguration dieser Plattformen einfügt. Nach der Ausführung müssen Sie den entsprechenden Editor oder das Tool neu starten.
Im Gegensatz dazu sollte code-review-graph build im Projektstammverzeichnis ausgeführt werden. Die offizielle Anleitung sagt: „Then open your project“ und lässt dann den KI-Assistenten den Code-Review-Graphen für „this project“ erstellen. Gleichzeitig muss die Ignore-Datei .code-review-graphignore explizit im Repository-Stammverzeichnis platziert werden, während die lokalen Graphdaten im Verzeichnis .code-review-graph/ im Projekt gespeichert werden. Mit anderen Worten: install integriert die Fähigkeit in Ihr KI-Tool, während build den Graphen für das aktuelle Repository erstellt.
Um Verwirrung zu vermeiden, können die Zuständigkeiten der beiden Befehle auch direkt gegenübergestellt werden:
Befehl | Wird im Projektstamm ausgeführt? | Funktion |
|---|---|---|
| Nein, muss nicht im Projektstamm ausgeführt werden | Erkennt KI-Tools auf dem Rechner und schreibt entsprechende MCP-Konfiguration |
| Ja, muss im Stammverzeichnis des Zielprojekts ausgeführt werden | Erstellt einen lokalen Graphen für das aktuelle Repository und generiert |
Wenn der Editor selbst keine Hooks unterstützt oder der Graph im Hintergrund ständig auf dem neuesten Stand gehalten werden soll, kann auch der Daemon-Modus verwendet werden. Die offizielle Dokumentation bietet Befehle wie crg-daemon add, crg-daemon start, crg-daemon status usw., um mehrere Repositorys zu registrieren und Dateiänderungen automatisch zu überwachen.
Häufig verwendete Befehle
Neben Installation und Graphenerstellung bietet die offizielle Dokumentation auch eine recht vollständige CLI-Funktionalität.
Befehl | Funktion |
|---|---|
| Automatische Erkennung und Konfiguration aller unterstützten Plattformen. |
| Nur die angegebene Plattform konfigurieren. |
| Komplette Analyse des aktuellen Codebestands und Erstellung des Graphen. |
| Nur inkrementelle Aktualisierung für geänderte Dateien. |
| Kontinuierliche Überwachung von Dateiänderungen und automatische Aktualisierung des Graphen. |
| Erzeugt einen interaktiven HTML-Graphen, auch exportierbar als GraphML, SVG, Obsidian vault oder Neo4j Cypher. |
| Generiert automatisch ein Markdown-Wiki basierend auf der Community-Struktur. |
| Führt eine Änderungsauswirkungsanalyse mit Risikobewertung durch. |
In Tools, die Slash Commands unterstützen, können auch die Befehle /code-review-graph:build-graph, /code-review-graph:review-delta und /code-review-graph:review-pr verwendet werden, um die entsprechenden Workflows aufzurufen.
Wie effektiv ist es?
Offizielle Benchmarks basieren auf 6 echten Open-Source-Repositorys und 13 Commits. Die Ergebnisse zeigen, dass der Graph-Modus im Vergleich zum naiven vollständigen Einlesen den Token-Verbrauch im Durchschnitt auf etwa ein Achtel reduziert, also eine Reduktion um den Faktor 8,2. Aus öffentlichen Daten geht hervor, dass die Gewinne nicht bei allen Repositorys gleich sind, aber die meisten mittleren bis großen Projekte eine deutliche Reduktion aufweisen.
Projekt | Token-Reduktionsfaktor |
|---|---|
Gin | 16,4× |
Flask | 9,1× |
FastAPI | 8,1× |
Next.js | 8,0× |
httpx | 6,9× |
Durchschnitt | 8,2× |
Ein weiterer wichtiger Indikator ist die Genauigkeit der Auswirkungsanalyse. Die offiziellen Ergebnisse zeigen einen Recall von 100%, einen durchschnittlichen F1-Wert von 0,54 und eine durchschnittliche Precision von 0,38. Dies deutet darauf hin, dass die Strategie eher konservativ ist: Es werden lieber etwas mehr „möglicherweise betroffene“ Dateien angezeigt, als tatsächlich von einer Änderung betroffene Abhängigkeiten zu übersehen.
Kennzahl | Wert | Bedeutung |
|---|---|---|
Recall | 100% | Lässt keine tatsächlich betroffenen Dateien aus |
F1 | 0,54 | Misst das harmonische Mittel von Recall und Precision |
Precision | 0,38 | Ist eher konservativ, kann mehr Kandidatendateien einbeziehen |
Allerdings ist dieser Ansatz nicht in allen Szenarien überlegen. Die offizielle Dokumentation weist explizit darauf hin, dass in kleineren Projekten mit sehr lokalen Änderungen der Kontextaufwand der Graph-Metadaten selbst größer sein kann als die Kosten des direkten Einlesens der Dateien. Beispielsweise betrug die Reduktion bei einem Einzeldatei-Test von express nur 0,7×. Daher ist es am besten geeignet für mittlere bis große Projekte, Änderungen an mehreren Dateien, komplexe Abhängigkeiten und hochfrequente KI-Review-Workflows.
Für welche Teams ist es geeignet?
Wenn ein Team Claude Code, Codex, Cursor oder ähnliche Tools bereits in den täglichen Entwicklungsprozess integriert hat und das Projekt relativ groß ist, die Modulbeziehungen komplex sind und PR-Reviews häufig stattfinden, dann ist der Wert von code-review-graph recht direkt. Es ersetzt im Wesentlichen nicht die Code-Review, sondern hilft der KI zunächst dabei, richtig zu bestimmen, „was gelesen werden soll“, sodass nachfolgende Reviews, Debugging, Architekturanalysen und Onboarding auf einem genaueren Kontext basieren.
Für Ein-Personen-Projekte, sehr kleine Repositorys oder gelegentliche einfache Änderungen bringt es nicht immer spürbare Vorteile. Für Teams, die jedoch systematisch KI-Codekosten senken, Kontextrauschen reduzieren und die Treffsicherheit von Code-Reviews verbessern möchten, hat es bereits eine recht praktische Wirksamkeit gezeigt.
Auf Google folgen
HeyBinyang als bevorzugte Quelle bei Google hinzufügen
Wenn du meine Updates über Google leichter finden möchtest, kannst du diese Website als bevorzugte Quelle markieren.
Teilen
Teilen
Diesen Artikel teilen.